
#17 Indexing and Optimization
SQL Crash Course #17


All the course material is stored in the SQL Crash Course repository.
Hi everyone! Josep and Cornellius Yudha Wijaya from Non-Brand Data here 👋🏻
As promised, today we are publishing the next two issues of our SQL Crash Course – From Zero to Hero! 🚀
I am sure you are here to continue our SQL Crash Course Journey!📚
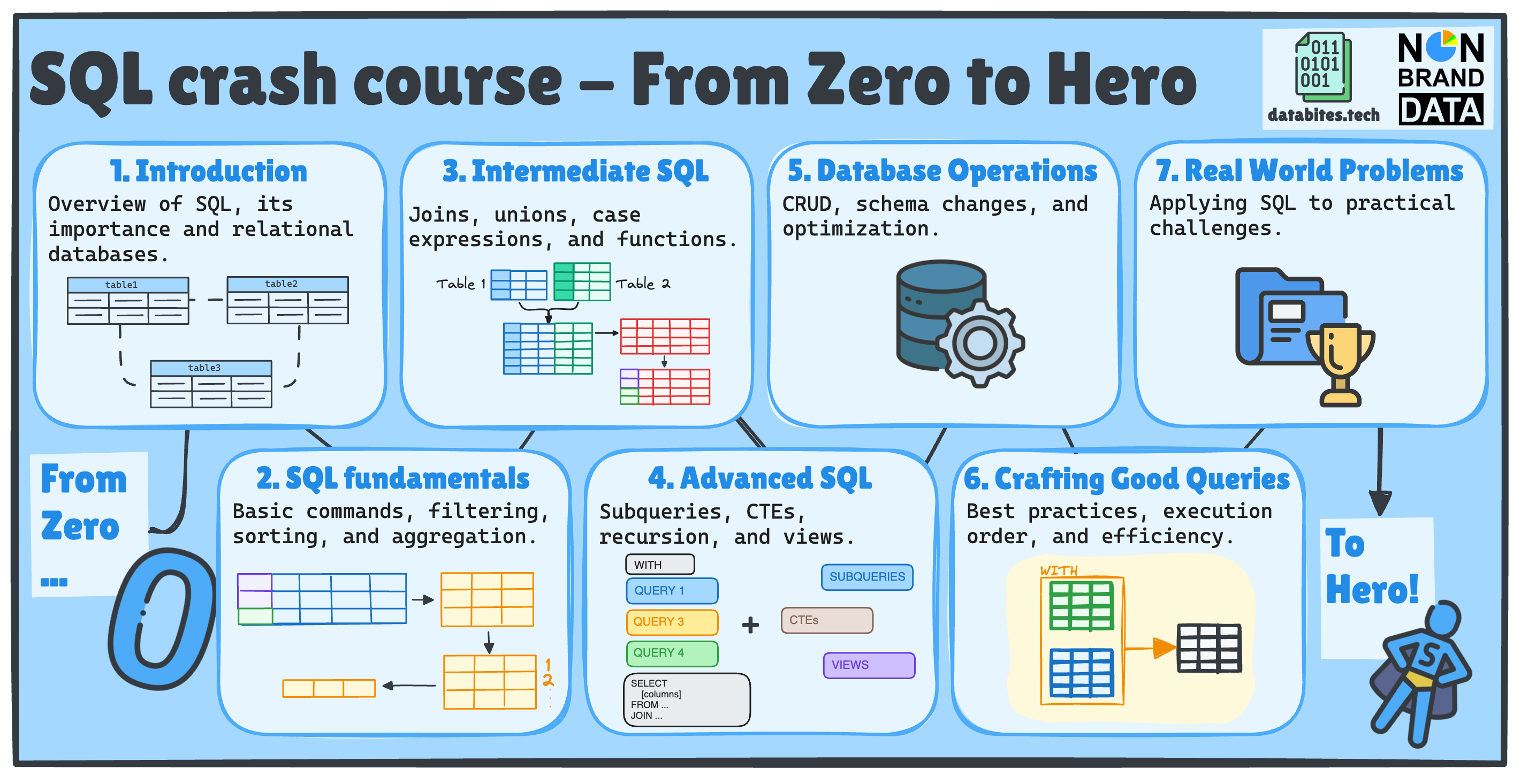
If this is your first time or you’ve forgotten what we’ll cover, we will examine seven key SQL topics, each divided into multiple posts across Non-Brand Data and DataBites.

📚 Previously in Database Operations…
Remember last time we already saw:
📌 #15 – CRUD Operations:
📌 #16 – Database Modification
In today’s topic, we will finish up the Database Operations topic with:
📌 #17 – Indexing and Optimization:
Today, we will also explore an exciting new topic in our SQL learning:
Modular Code ♻️
Which we will start with the exciting article:
📌 #18 – Generating Modular Code with CTEs by Josep Ferrer in DataBites
So don’t miss out—let’s keep the SQL momentum going!
🗂️ What is SQL Indexing?
An index database structure speeds up data retrieval by acting like a book's index. Instead of scanning every row (a full table scan), the database uses indexes to locate data quickly.
We can say that the index is a separate data structure (like a table of contents) that:
Stores a sorted copy of selected column values
Maintains pointers to actual table rows
Enables fast lookups without scanning the entire table
Indexes help retrieve data from the database much more quickly. We cannot see the indexes as they are only used to speed up the search process. Although updating a table with an index might take longer, as indexes also need to be updated, we should only index tables we access often.
⚡ Why Use Indexes?
Indexes optimize queries by:
Reducing I/O operations during searches.
Minimizing full table scans.
Accelerating JOIN, ORDER BY, and GROUP BY operations.
⚖️ The Tradeoff: Index Costs
While indexes speed up READS, they impact WRITES:
INSERT: Must update all relevant indexes
UPDATE: Indexes on modified columns need rebuilding
DELETE: Index entries must be removed
🎯 When to Use Indexes
These are the cases why you want to use Indexes.
Frequent Search Columns
JOIN Conditions (foreign keys)
Columns in WHERE, ORDER BY, or GROUP BY
High-Cardinality Data (columns with many unique values)
✨When NOT to Index
In contrast, you might not want to use the index in these cases.
Small tables (<1000 rows)
Frequently updated columns
Low-cardinality columns (e.g.,
genderwith M/F values)Infrequently queried columns
✅Key Index Types
There are a few Index types, including:
Clustered Index: Sorts and stores data rows physically (e.g., PRIMARY KEY).
Non-Clustered Index: Separate structure with pointers to data (like a glossary).
Composite Index: Indexes multiple columns for multi-column queries.
Covering Index: Includes all columns needed for a query, eliminating table access.
🏗️ Indexing in Action
Let’s see examples of the Indexing during real-time scenario.
1️⃣ Clustered Index
Example: newsletters.id (Primary Key)
-- Inherently created when you defined:
CREATE TABLE newsletters (
id VARCHAR(10) PRIMARY KEY, -- Clustered index created here
name VARCHAR(100)
);Query Benefiting:
SELECT * FROM newsletters WHERE id = '1112A';How It Works:
Data is physically sorted by
idon diskDirectly jumps to '1112A' like finding a chapter in a book
Without Clustered Index:Full Table Scan → Checks every row until finding '1112A'
Key Takeaway: Perfect for PRIMARY KEY lookups and range queries on IDs.
2️⃣ Non-Clustered Index
(Specialized Search Assistant)
Example: Filter posts by name
CREATE INDEX idx_posts_name ON posts(name);Query Benefiting:
SELECT * FROM posts WHERE name = 'DataBites';How It Works:
Index Structure:
'DataBites' → Pointer to Row 5
'RAG model basics' → Pointer to Row 3
'SQL basics' → Pointer to Row 1Scans the index instead of the whole table
Follows the pointer to the exact row
3️⃣ Composite Index
Example: Find recent posts in a newsletter
CREATE INDEX idx_newsletter_published
ON posts(newsletter_id, published_at);Query Benefiting:
SELECT * FROM posts
WHERE newsletter_id = '1112A'
AND published_at > '2024-03-01';How It Works:
Index Structure:
('1111B', '2024-03-05') → Row 3
('1112A', '2024-01-10') → Row 1
('1112A', '2024-02-15') → Row 2
('1112A', '2024-05-01') → Row 5Finds '1112A' entries first
Then filters by date within those
Performance: 450ms → 15ms (30x faster)
4️⃣ Covering Index
Example: Aggregate interaction points
CREATE INDEX idx_interactions_covered
ON interactions(post_id, points) INCLUDE (datetime);Query Benefiting:
SELECT post_id, SUM(points)
FROM interactions
GROUP BY post_id;How It Works:
Index Contains:
(post_id | points | datetime)
'1111B001' | 2 | 2024-01-06
'1111B002' | 5 | 2024-04-18
'1111B002' | 8 | 2024-01-04Aggregates directly from the index
Never touches actual table data
🚫 Common Pitfalls & Pro Tips
Over-Indexing: Too many indexes slow down writes (INSERT/UPDATE/DELETE).
Under-Indexing: Critical queries suffer without necessary indexes.
Fragmentation: Rebuild indexes periodically for peak performance.
Use Covering Indexes: Include frequently accessed columns to avoid key lookups.
Optimize Thoughtfully: Like a well-organized library, strategic indexing ensures your database delivers results swiftly and efficiently. 🚀
🛠️ SQL Optimization Techniques Beyond Indexing
Avoid
SELECT *: Fetch only needed columns.Use EXISTS over IN: For existence checks.
Normalize/Denormalize Tables: Balance redundancy and joins.
Limit Subqueries: Opt for JOINs where possible.
Analyze Execution Plans: Identify bottlenecks with
EXPLAIN.
✅ Conclusion
You can treat your database like a cluttered storage room 🗃️ — slow, chaotic scans through every box (row) to find what you need.
Or like a well-organized library 📚 — indexes act as instant lookup catalogs, guiding you straight to the right shelf (data).
Smart indexing transforms your queries:
Faster → Skip full-table scans with sorted shortcuts
Leaner → Fetch only what’s needed, no wasted effort
Smarter → Balance speed (reads) and upkeep (writes)
And once you see the results—you’ll index everything (but don’t… we covered why 😉).
👉🏻 SQL playground with Index Example
How to Get Started 🚀
Over the coming weeks, we’ll guide you through:
✅ SQL Fundamentals
✅ Intermediate SQL
✅ Advanced SQL
✅ Database Operations
✅ Writing Efficient Queries
Once you grasp the basics, practice is key! Start working on real-world projects and solving hands-on data problems.
What’s Next? ➡️
This is the first of many posts about the upcoming SQL Courses. It will only explain what SQL is in its crude form.
To get the full experience and fully immersed in the learning:
👉 Subscribe to Databites.tech (By Josep)
👉 Subscribe to Non-Brand Data (By Cornellius)
👉 Check out the SQL Crash Course GitHub repo
👉 Share with your friend and whoever needs it!
🗓️ Every Thursday, you will have two new issues in your inbox!
Let’s dive in and make SQL less scary, more fun, and way more useful! 🚀
Josep & Cornellius