
23 RAG Pitfalls and How to Fix Them
Few things that you need to avoid when working with your RAG applications


Retrieval-augmented generation (RAG) combines large language models (LLMs) with external knowledge retrieval to produce more accurate and grounded outputs. In Theory, RAG should reduce hallucinations and improve factuality. However, many RAG systems still yield incomplete answers, irrelevant documents, or confidently wrong information in practice.
For those interested in learning about technical implementation, here is an article on implementing a simple RAG. Moreover, check out the RAG-To-Know series to learn more!
Simple RAG Implementation With Contextual Semantic Search

Hi everyone! Cornellius here, back with another Lite series. This time, we’ll explore the advanced techniques and production methods of Retrieval-Augmented Generation (RAG)—tools that will be helpful for your use cases. I will make it into a long series, so stay tuned!
This article will identify 23 common pitfalls across the RAG lifecycle and offer practical fixes for each to help you build reliable RAG applications.
Curious about it? Let’s get into it!
Let’s divide the pitfalls into a few sections, which include the:
Data & Indexing
Retrieval & Ranking
Prompt & Query
System & Scale
Safety, Evaluation & Trust
We will start exploring them one by one.
Data & Indexing
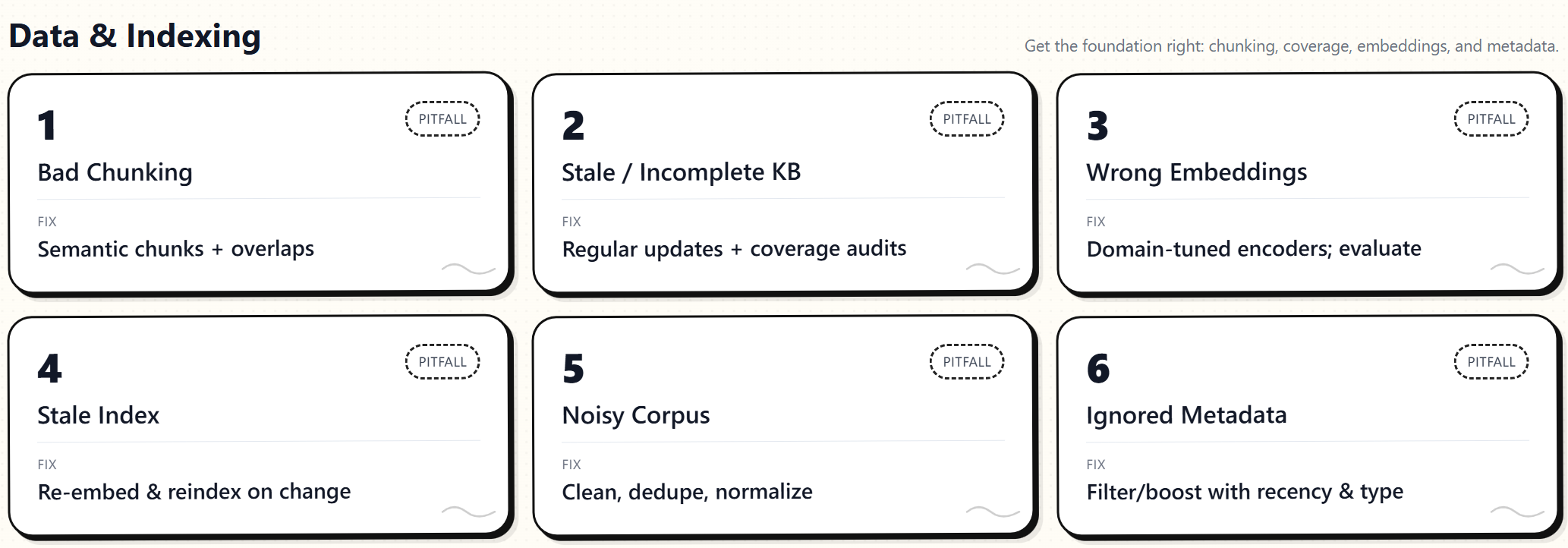
1. Poor Chunking of Content
Breaking source documents into inappropriate chunks can lead to the loss of context or the omission of important information. Fixed-size or arbitrary chunks might cut important content, such as splitting a table or paragraph in the middle, causing nonsensical fragments. If chunks are too large, they can overflow prompts or include irrelevant text; too small, and meanings break apart.
Use more effective strategies, such as overlapping chunks or varying sizes based on content. Tools like LangChain’s TextSplitter create meaningful, semantic, or paragraph-based chunks. Overlapping windows maintain context. Keep chunks within the LLM’s context window, about 50–75% of max tokens. Chunk at natural boundaries with overlaps to preserve context and enhance retrieval. Adjust rules if important facts get split.
2. Outdated or Incomplete Knowledge Base
If the knowledge corpus lacks information to answer a query, the model cannot provide a grounded response. Missing or outdated data can lead to vague, incorrect, or inaccurate answers. A RAG system can only retrieve indexed content; gaps or outdated facts lead to errors.
Maintain a comprehensive and current knowledge base by regularly updating content, auditing for gaps, and incorporating relevant data. Use a data freshness pipeline to timestamp documents and update or archive outdated ones. Enrich your dataset in areas with frequent empty queries through additional sources or curation. Remember, RAG relies on what exists, so invest in building a comprehensive, up-to-date resource.
3. Using an Unsuitable Embedding Model
Choosing the right embedding model for indexing and query encoding is vital. An outdated or mismatched model fails to capture query meaning alongside documents, harming retrieval. A generic encoder may overlook domain-specific terms, and older models may struggle to comprehend evolving vocabulary or contexts, resulting in relevant documents being overlooked or yielding low similarity scores.
Choose and fine-tune your embedding model carefully. Pick a model that aligns with your domain, such as BioBERT for biomedical texts or LegalBERT for legal documents. Newer or fine-tuned models usually offer better semantic understanding of queries.
Always evaluate candidate models on your data, as expert advice emphasizes. Optimize embedding models with domain-specific question-document pairs for improved relevance. Consider the vector size, as larger vectors capture more detail but require more computation. Choosing a suitable, up-to-date embedding and customizing it helps ensure effective retrieval.
4. Not Updating Embeddings and Index
A “stale” index occurs when your documents or embedding model change, but the vector index hasn’t been refreshed. Embeddings from previous versions may no longer accurately reflect current content or language understanding. Language shifts and new terms emerge over time; without re-embedding data, retrieval accuracy drops. Studies show outdated embeddings can cause performance declines of up to 20% in some LLM tasks. In short, an unupdated index will increasingly fail to retrieve accurate info.
Re-index regularly and monitor embedding drift. When updating the knowledge base with new or revised documents, generate and add their embeddings. Re-encode the corpus with a better or fine-tuned model. Implement periodic updates, such as monthly or when data changes exceed a threshold. Version embeddings and conduct A/B tests to compare performance, ensuring improvements. This prevents semantic drift and maintains retrieval accuracy over time.
5. Low-Quality or Noisy Data in the Corpus
Garbage in, garbage out. Poorly written, duplicate, outdated, or irrelevant data in your retrieval corpus can introduce noise, confusing the LLM. Noisy data risks incorrect facts or distractions, especially in sensitive fields like healthcare or finance, where inaccuracies can be serious quality of RAG outputs depends on the quality of the data you feed into it.
Clean and organize your knowledge base by removing duplicates, errors, and unrelated text before indexing. Standardize formats, such as units and names, to minimize confusion. Lightly label unstructured data with tags, such as topics or dates, to enhance searchability. Add noise filtering using heuristic rules or classifiers to eliminate non-informative content. Resolve conflicts by trusting reputable sources and flagging outdated or conflicting data. A cleaner dataset enables the retriever to provide more relevant and accurate context for better LLM answers.
6. Ignoring Metadata and Contextual Signals
A common mistake is relying solely on text similarity for retrieval, ignoring metadata that could boost relevance. Pure vector search treats all documents equally, missing cues like recency, credibility, or type. This can cause important updates to rank below older, less relevant documents. Ranking by similarity alone often overlooks context or domain nuances. Not using metadata like timestamps, authors, or categories results in missing opportunities to prioritize relevant content.
Incorporate metadata into search and ranking. Modern engines outperform simple vector databases by leveraging signals like keywords, recency, and metadata.
Also, implement a hybrid strategy: first filter by metadata (e.g., relevant types, recent documents), then rank by semantic similarity. Boost documents matching the context, such as product category, using metadata-driven boosting. Include metadata explicitly in the algorithm (document type, author, date) for better prioritization. Many systems support filters or boosting on fields. Using metadata ensures results are relevant, contextually appropriate, and current.
Retrieval & Ranking

7. Over-Reliance on a Single Retrieval Method
Vector search can miss exact or specific matches. Semantic embeddings identify conceptually similar texts but may overlook details such as error codes or rare terms. Keyword search might miss paraphrases. Relying on a single method risks low recall or precision, depending on the query.
Utilize a hybrid approach that combines a semantic vector and a lexical keyword search for enhanced coverage. Many systems run both similarity and keyword queries, then merge the results to find exact matches, such as names or quotes, and broader semantic matches. Modern engines support integrating BM25 with vector similarity; if not, manually combine and weigh results. Using both methods ensures specific info is accessible without losing semantic benefits for fuzzy queries.
8. Retrieving Too Many or Too Few Documents
Selecting the correct number of documents (Top-K) is a delicate balance: too few can miss answers, while too many add irrelevant information. If K is too low, key evidence might be missed; if too high, the model gets overwhelmed or reaches context limits, truncating details. A fixed K isn’t ideal, since simple questions require fewer documents and complex ones more. Without tuning, resources are wasted or critical info is missed.
Enhance Top-K retrieval by testing various K values to find the optimal setting for your domain. Start with a moderate K (around 10), then narrow results to 3-5 relevant documents. Adjust K based on query complexity, retrieving more for complex questions and fewer for specific inquiries. If key information is not in the top results, consider increasing K or improving the ranking. Balance recall and precision by adjusting K and thresholds: reduce the number of documents if scores decline, or increase it if the query is broad. Review and refine K regularly to include important documents without overwhelming the LLM with irrelevant data.
9. Suboptimal Document Ranking
Even when the correct answer is in your corpus, weak retrieval ranking can hide it. The retriever may find the proper document, but place it below less useful results, so the LLM never sees it. Simple similarity scoring often misses nuance; long, vaguely related passages can outrank short snippets with the exact answer. The result is incomplete or irrelevant responses because the best evidence never reaches the model.
Tighten ranking with a multi-stage approach. Generate candidates quickly, then apply a cross-encoder reranker for deeper relevance. Verify your similarity metric (cosine vs inner product), add metadata boosts and domain rules, and fine-tune on labeled query–doc pairs. Track whether known-relevant documents appear in the top results and adjust K, reranking, and rules until they do. Avoid relying solely on raw vector scores; smarter reranking and signals yield more accurate answers.
10. Context Window Overflow and Truncation
LLM context windows are finite, so dumping lots of retrieved text or extensive passages often leads to truncation. Naively concatenating top-K chunks until the token cap can cut out critical details; conversely, stuffing everything in may cause the model to ignore the tail. Either way, key information never reaches the model, yielding incomplete or distorted answers.
Mitigate this by optimizing consolidation and filtering. Use concise, coherent chunks; pre-filter sentences or paragraphs by relevance; compress low-value material; and apply dynamic selection to drop low-ranked or overlapping content when tokens run tight. Preserve the pieces that directly answer the question and reserve budget for the user query and prompt prefix. By prioritizing high-value information and summarizing the rest, you keep essentials within the context window.
11. Noisy or Conflicting Retrieved Context
Sometimes retrieval brings back contradictory or irrelevant text alongside helpful facts. Mixed signals, such as an outdated policy next to a current one, can confuse the model and yield inaccurate or hedged answers. Extra irrelevant text becomes noise that distracts from the question. In customer support, for example, pulling both an old solution article and a newer, different recommendation can cause the answer to merge or misstate them.
Filter and refine the context before generation. Remove outdated documents when newer ones address the query, and eliminate off-topic passages using keyword or secondary relevance checks. Archive or tag older knowledge and prefer newer sources for retrieval. If both old and new information must be included, label them clearly in the prompt with dates so the model knows which to trust. Instruct the model to prioritize the most recent or most relevant content and deduplicate near-duplicate text. Supplying a clean, consistent context makes it easier for the model to extract the correct answer.

Prompt & Query
12. Poor Prompt Design and Instructions
Even with solid retrieval, a RAG system can fail if the prompt is poorly designed. Vague or incomplete instructions cause the model to ignore context, produce incorrect formats, or hallucinate. If you do not tell the model to rely only on the provided documents, it may mix in outside knowledge. If you need structured output but do not say so, you may get a rambling paragraph instead.
Clarify the format in the prompt. Separate the retrieved context from the question with explicit delimiters, for example:
“Context:\n[docs]\n\nQuestion:\n…”. Tell the model to ground its answer in the context and not invent facts. If a specific format is required, specify it, such as “Return a JSON object with these fields…”. When available, use structured output or function calling to enforce the schema.
Keep formatting instructions separate from content instructions. Provide a short example for complex tasks. Add wording that encourages faithful use of the context, such as “If the documents do not contain the answer, say ‘I don’t know’.” Finally, A/B test several prompt variants and keep the one that best matches the source data.
13. Not Handling Ambiguous or Broad Queries
Ambiguous or overly broad questions can confuse a RAG system. A vague query may match many documents or none with confidence, yielding a generic answer or a guess. Ask “Tell me about security,” and the system might retrieve piles of loosely related material, producing a high-level response that misses the user’s intent. Extremely broad prompts can also cause the model to select a narrow angle arbitrarily, resulting in off-target or uneven detail.
Add query understanding and refinement before retrieval. Rewrite or expand vague prompts into specific questions, or split them into subquestions. Where possible, ask the user for clarification or show example queries to set expectations. Detect underspecified patterns and handle them specially, for example, by offering a brief menu of possible topics. If both old and new information must be presented, label it clearly and acknowledge the breadth by providing a scoped outline of the areas to cover.
14. Failing to Address Multi-Part Questions
Complex questions often contain several subtopics. Treating them as a single retrieval and single-shot answer invites incompleteness: the model may answer one part and ignore the rest. For example, “What are the key points in documents A, B, and C?” can yield only A if retrieval misses B and C or the model gravitates to the easiest piece. The result is a partial answer that fails the user.
Break the problem into parts. Break down the query into specific subquestions, retrieve evidence for each, and then merge the results. Add an upfront analysis step to detect subcomponents, and instruct the model explicitly to cover all parts, for example: “This question has multiple parts. Address each: (1) … (2) … (3) …”. Use multiple retrievals or a broad first pass followed by targeted lookups per topic. Apply quiet query rewriting behind the scenes so “key points in A, B, C” becomes three focused queries. Finally, prime for completeness with guidance like “give a comprehensive answer,” and verify length and coverage before returning the result.
System & Scale

15. High Latency in Retrieval or Generation
RAG pipelines span multiple components such as vector search, rerankers, and the LLM, which naturally adds latency. Without optimization, response times slip as indexes grow and traffic rises. Typical culprits include brute-force search over extensive collections, network overhead to external APIs, and serving big models on underpowered hardware. Under peak load, the system can queue requests, frustrating users and breaking near-real-time use cases.
Tune performance end-to-end. Use approximate nearest neighbor indexes, such as HNSW or FAISS IVF, and adjust parameters (e.g., efSearch or nprobe) to balance speed and recall. Add caching for frequent query embeddings, retrieval results, and reusable answers where appropriate. Cut network delays by choosing nearby regions or hosting a smaller model in-house. Scale horizontally with a distributed vector store and autoscaled model serving. Trim prompts and instruct concise outputs to minimize token count. Route simple queries to a lighter model or use a two-stage approach. By profiling and fixing hotspots in search, inference, and networking, you can keep responses in the sub-second to a few-second range even as data and concurrency grow.
16. Poor Scalability Planning
RAG prototypes often look fine on small corpora and low traffic, then stumble at scale. Memory spikes from embedding millions of documents, long index build times, and throughput collapse under concurrency are common. Very large or frequently updated indexes are challenging to keep up to date, and a model that serves one user smoothly may struggle at high QPS. If the stack cannot scale horizontally, costs and instability rise quickly.
Scale design early. Utilize distributed, sharded vector stores and select ANN structures that are well-suited to the size and update rate. Combine keyword prefiltering with vector search to avoid scanning the entire corpus each time. Prefer engines that support incremental or near-real-time indexing. Treat pure vector stores that require batch reindexing with care, and consider autoscaling model serving and load balancing across replicas. Control footprint by utilizing dimensionality reduction or quantization, and closely monitor memory usage. Add backpressure, caching, and SLOs; profile and mitigate hotspots. By pairing distributed architecture with hybrid retrieval, incremental indexing, and right-sized models, you can grow data and traffic without performance cliffs.
Safety, Evaluation & Trust
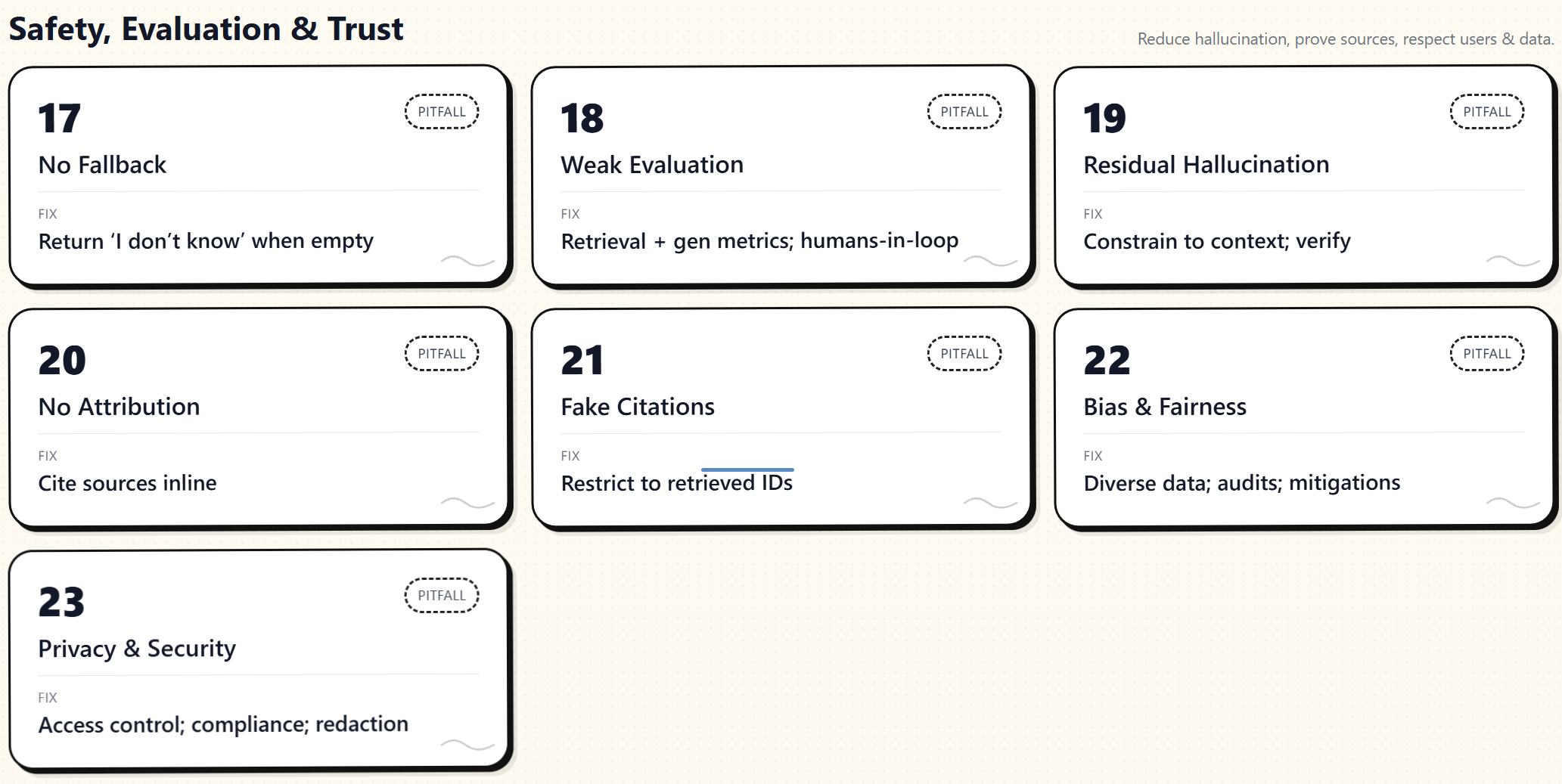
17. No Fallback for Unanswerable Queries
When the knowledge base cannot answer a question, many RAG systems still produce a response, which often becomes a hallucination. The model may confidently invent details instead of admitting uncertainty, especially for niche topics with no coverage. This undermines trust because users cannot determine that the system lacked evidence.
Handle these cases explicitly. Detect low-confidence retrieval by watching similarity scores or reranker signals, and if nothing relevant appears, return a clear “I don’t know” or a brief apology instead of generating. Inform the model upfront to answer only from the provided context and to state that it does not know when evidence is missing. Optionally, fall back to another source, such as a web search, if permitted by policy. Log these “no answer” queries to guide corpus expansion, and set thresholds that block generation when evidence is insufficient. This transparent behavior preserves user trust and prevents misleading outputs.
18. Inadequate Evaluation and Monitoring
RAG outputs are complex to evaluate automatically. Relying on generic text metrics or a handful of test questions can hide silent failures. BLEU and ROUGE do not catch factual mistakes or missing evidence, and evaluating only the final answer can mask retrieval weaknesses. Systems that appear to function properly in a demo may perform poorly when subjected to real-world queries.
Build a full evaluation stack. Measure retrieval with Recall@K and MRR on queries where relevant documents are known. Judge generation for factual accuracy, relevance, and coherence, and add human or domain-expert review to verify that the retrieved text supports claims. Include task-specific checks, such as fact verification, when applicable. Create a robust test set and automate runs to catch regressions early.
Monitor in production. Log samples, review them for correctness and user satisfaction, and collect lightweight feedback signals. Combine quantitative metrics with qualitative assessment to surface failure modes and iterate. Avoid one-dimensional evaluation and bake these practices into the development cycle from day one.
19. Persisting LLM Hallucinations
RAG reduces hallucination but does not eliminate it. Models can still invent details when retrieval is incomplete or slightly off, often blending prior knowledge with the provided context. These additions can sound confident and plausible, so users may trust statements that are not actually supported by the documents. The risk is highest when answers contain unsourced claims that look grounded but are not.
Tighten grounding and add verification. Tell the model to use only retrieved sources and require fine-grained citations, so that each claim is mapped to a specific reference. Run a post-generation fact check to confirm that every statement appears in the retrieved text, or have the model highlight which source supports each line.
Where possible, use constrained generation or quote key passages directly. Encourage the model to say “I don’t know” when evidence is missing. Monitor for unsupported content using simple string or embedding checks, and continually improve retrieval precision so the model has the proper evidence from the start.
20. Lack of Source Attribution for Answers
Answers without citations force users to take the output on faith. That diminishes trust and hides whether claims are grounded in the documents. One of RAG’s key advantages is traceability to sources; without attribution, responses are indistinguishable from a generic model, and paraphrases become hard to verify.
Make attribution a first-class feature. Instruct the model to cite the document used for each claim (for example, “[Doc 2]”), or present bullet points with links to sources. Highlight matching spans in the UI so users can inspect the evidence. This nudges the model to stay close to the retrieved text, reducing hallucination.
Aim for fine-grained attribution when you can, even at the sentence level. At a minimum, include a short list of sources used. Turning every answer into open-book QA increases transparency and user confidence.
21. Model Fabricating References or Citations
LLMs can generate citations that appear genuine. If you ask for sources without constraints, the model may invent case names, papers, or URLs because it is not checking a database. These fake references are worse than no citation, as they create a false sense of credibility and are difficult to refute on the spot.
Constrain citation to real, retrieved documents. Assign each retrieved item an ID, such as [1] and [2], and instruct the model to cite only from that list. Reject any citation not in the allowed set. A safe pattern is two-stage: generate the answer using only the provided context, then attach citations by matching each claim to a retrieved source. Add automated checks that look up each cited ID in your index or repository and flag missing ones. Provide examples of correct citation use in the prompt, and never ask the model to invent sources. This keeps attribution trustworthy and prevents embarrassing, fabricated references.

22. Bias and Fairness Issues in Retrieval or Generation
RAG pipelines can inherit bias from both retrieval and generation. If the corpus is skewed by gender, race, ideology, or region, the retrieved context will reflect that, and the model may amplify it rather than correct it. Ranking can also favor popular or majority sources, burying minority viewpoints. Assuming RAG is safe because it uses “factual” data is risky; the result can be unfair answers, gendered language, or region-specific bias that harms trust and reputation.
Address bias across data, retrieval, and generation. Curate a diverse corpus and document coverage gaps. Use metadata and diversity constraints to vary sources in results. Add bias checks to outputs, with prompts or rules that avoid stereotypes, and fine-tune the model if patterns persist. Randomize among equally relevant documents to reduce systematic tilt. Probe the system with targeted tests, include domain experts and diverse reviewers, and track fairness metrics alongside accuracy.
Bias is often invisible until you look for it, so make testing and mitigation a permanent part of your development and evaluation process.
23. Neglecting Data Privacy and Security
RAG often draws on proprietary or sensitive data. If you ignore privacy, security, and compliance, the model can expose confidential information to the wrong users, leak verbatim text from protected documents, or surface copyrighted content. Regulations like GDPR or CCPA may also restrict the retention and handling of personal data. Treating the corpus as an open pool invites legal, ethical, and reputational risk.
Mitigate this with strict governance. Enforce permission-aware retrieval (metadata filters, separate indexes), apply least-privilege access, and redact or anonymize personal identifiers. Use encryption at rest and in transit, and exercise caution when using third-party APIs; consider self-hosting for high-security contexts. Keep audit logs, support deletion requests, and limit verbatim output to respect copyright. Minimize data retention and obtain consent where required. Bake privacy and security into design and operations, and run regular audits to prevent leaks and misuse.
Love this article? Comment and share them with Your Network!
Insightful 💡