
3 Missing Data Types and the suggestion to handle it
Know what to know about the missing data

Know what to know about the missing data

During data cleaning and exploration, I am sure that everyone would agree that missing data is often encountered. Moreover, I usually get from people, “What should I do with the Missing Data?”. For that question, let’s define the missing data and the missing data classifications.
Missing Data
In statistics, Missing Data is a condition where no data value is present in the variable or observation. It is different from the category “Nothing” or “None” or anything else, stating that this data belongs to some category. Missing data is just missing, no value present.
Missing data could be classified based on the missing reason, they are:
Missing Completly at Random (MCAR). This is where the events that lead to any particular data-item being missing are independent. Not related to any observable items or other variables. It occurs randomly, without any pattern. What is great about MCAR is that the analysis would always be unbiased, but it is scarce to have an MCAR case.
Missing at Random (MAR). This is when the missing data is not random, but the missing data could be related to the other variables or observations. For example, there is a question, “Are you sick? If yes, please state your symptoms”. If I say yes to the question, then the symptoms' data would be present; hence, if I say no, then the symptoms' data would be missing because we did not fill this data. This is why the missing data is classified as Missing at Random because it is related to the other variables.
Missing not at Random (MNAR). This is where the missing data is neither MAR nor MCAR. The reason might be affected by some hypothetical value (Younger people tend to not fill the phone number because of security reasons) or indirectly affected by other variable value (Director less likely to fill the salary column, here the missing value is related to the occupation value). The missingness of MNAR is specifically related to what is missing, and MNAR data cases are often hard to resolve. It requires domain knowledge and a deeper understanding of the data to obtain an unbiased parameter.
I often ask, “What would you do with missing data?” to a Data Science fresher, and most of the time, their answer would be “Removing the data.” While it is not wrong to do this, it depends on the missing data reason.
Removing missing data in the MNAR condition could lead to bias, while removing missing data in the MCAR condition would be safe. It really depends on the condition after all.
So, what to do with the missing data after all? Remove or Imputation? Let’s see a few methods we could do.
Deletion
1.List-Wise Deletion (Complete-Case Analysis)
By far, this is the most simple approach, and many people use it. What you need to do is remove the row which contains the missing data.
List-Wise deletion is a safe bet if there is a large enough sample, where power is not an issue, and the assumption of MCAR is satisfied; however, when there is not a large sample or the assumption of MCAR is not satisfied. Listwise deletion is not the optimal strategy. You would introduce bias as well in this condition.
2. Dropping Variables
Dropping variables is another viable option if there are too much missing data in your variable; However, I believe that keeping the data is a much better option than dropping it. Why? Because you still need to see what kind of missing data we are dealing with. Depend on the classification I explain above; Missing data is data itself if you classify it right.
In my opinion, imputation is a much better way than deleting data.
Imputation
1. Classical way: Mean, Median or Mode
This is a basic statistical way to filling missing data; basically, you fill the missing data using the mean, median, or mode of the variable. It fills the data, assuming that the missing data would follow the variable's most frequent data.
There is also a method that you could do by filling in the missing variables based on another variable, for example, in the table below.
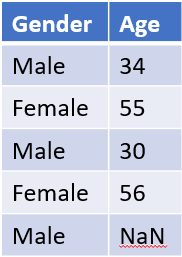
We have missing data in the age variable, and we want to fill it. Instead of taking the Age's mean, we could take the Age to mean for the Male gender.
This method's weakness is that we would reduce the variance within the variable as we take the data on its own.
2. Classical Way: Zero or Constant Value
Another way to fill the missing value is by filling it with a 0 or some constant number. It works well with categorical variables but sadly would introduce a lot of bias if you use it to numerical variables.
3. Machine Learning-Based: K-NN
There are many ways to impute the missing value based on machine learning, but I would only talk about the K-NN. The K-NN or k-nearest-neighbors is an algorithm used for simple classification by using feature similarity to predict the values of any new data points. The prediction comes from the closeness of the new data point with the training data.
K-NN method requires the selection of the number of nearest neighbors and a distance metric. We set the K as an integer number and setting an appropriate distance metric based on the variables.
The distance metric, e.g.:
1. Continuous Data: The commonly used are Euclidean, Manhattan, and Cosine
2. Categorical Data: Hamming distance
4. MICE (Multivariate Imputation by Chained Equations)
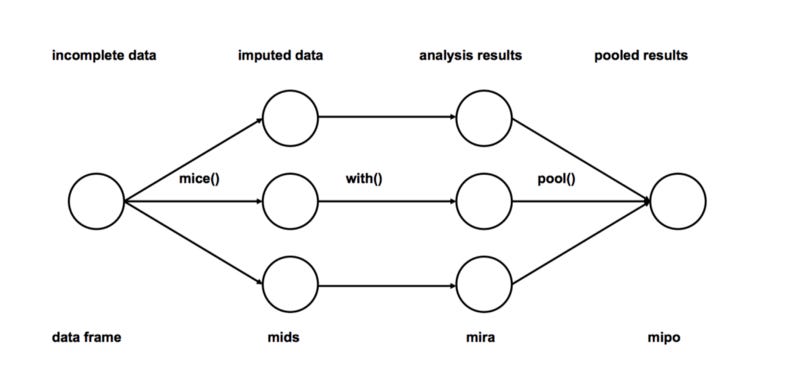
This imputation works by filling in the missing data multiple times using the Multiple Imputations (MIs) concept. Multiple Imputation is better than a single imputation because it measures the uncertainty of the missing values better. For more information on the algorithm, you can check the Research Paper
We could test the method by a dataset example. If you do not have the impyute module, you should install it first.
pip install impyutefrom impyute.imputation.cs import miceimport seaborn as snsmpg = sns.load_dataset('mpg')mpg.head()
This is the mpg dataset that we have; if we examine it further, the ‘horsepower’ variable contains missing data.
mpg[mpg['horsepower'].isna()]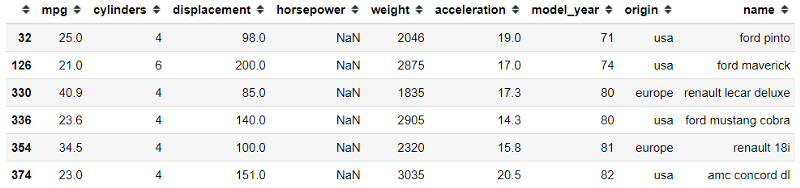
We might then want to fill the missing data by using the horsepower and weight information as it is correlated.
# start the MICE trainingimputed_training=mice(mpg[['horsepower', 'weight']].values)mpg['horsepower'] = imputed_training[:, 0]When it is finished, you could check the missing data once more, and it surely filled by the MICE imputation.
Conclusion
There are 3 kinds of missing data out there:
Missing Completly at Random (MCAR),
Missing at Random (MAR),
Missing not at Random (MNAR),
How you filling the missing data thou depends on the missing data classification and what kind of trade-off you want.
I hope it helps!