
3 Pandas Trick to Easing Your Data Life
Few Pandas tricks you could apply in your everyday work

Few Pandas tricks you could apply in your everyday work

As a Data Scientist, our everyday work is consists of pulling out the data, understand the data, cleaning up the data, transforming the data, and creating new features. Notice I did not include creating a machine learning model? Because creating a model would be the last thing we did, and it is not necessarily our everyday work. Cleaning data, however, is daily work.
For the reason above, I want to present to you three beautiful Pandas tricks to make your data work a little bit easier.
1. Using query for data selection
Data selection is the most essential activity you would do as a Data Scientist, yet it is one of the most hassle things to do, especially when it is done repeatedly. Let me show you an example.
#Let's use a dataset exampleimport pandas as pdimport seaborn as snsmpg = sns.load_dataset('mpg')mpg.head()
Above is our dataset example, let’s say I want to select the row that either has mpg less than 11 or horsepower less than 50 and model_year equal to 73. This means I need to write the code just like below.
mpg[(mpg['mpg'] < 11) | (mpg['horsepower'] <50) & (mpg['model_year'] ==73)]
This is the usual way to selecting data, but sometimes it is a hassle because of how wordy the condition is. In this case, we could use the query method from the Pandas Data Frame object.
So, what is this query method? It is a selection method from Pandas Data Frame with a more humanly word. Let me show you an example below.
mpg.query('mpg < 11 or horsepower < 50 and model_year == 73')
The result is exactly the same as the usual selection method, right? The only difference is with a query we have a less wordy condition, and we write it in the string where the query method accepts string English words like in the example.
Another simple difference between the usual selection method and the query method is the execution time. Let’s take a look at the example below.

The usual selection method takes 18ms, and the query method takes 13ms to execute the code. In this case, the query method is a quicker selection method.
2. Replace values with replace, mask and where
While we are working with the data, I am sure there is a time where you need to replace some values in your columns with other specific values. It could be quite bothersome if we do it manually. Let’s say in my mpg dataset before I want to replace all the cylinders integer value into a word string value. Let me give you an example of how to replace it manually.
def change_value(x): if x == 3: return 'Three' elif x == 4: return 'Four' elif x == 5: return 'Five' elif x == 6: return 'Six' else: return 'Eight'mpg['cylinders'] = mpg['cylinders'].apply(change_value) mpg.head()
In the simplest case, we need to use the apply method from the Pandas Data Frame object, or maybe you could manually do it by using for loop method. In either way, it would be bothersome to do it each time you need to replace a value.
In this case, we could use the replace method from the Pandas Data Frame object. This is a method that specially used to help us replace specific values in the Data Frame. Let me show you an example below.
mpg.replace({'cylinders' : {3: 'Three', 4: 'Four', 5: 'Five', 6: 'Six', 8 : 'Eight'}}, inplace = True)mpg.head()
The results are the same, the only difference is how short the line we used to replace the values. In my example above, I used the dictionary object to specify which columns I want to replace the values are and another dictionary inside the dictionary to selecting which values I want to replace and the replacement values. In other words, it could be summarized such as {columns name: {values in the columns: replacement values}}.
What if you want to replace the values but with a particular condition. In this case, we could try to use the mask method. This method is an if-then method that works the best in the Series object rather than the Data Frame object. Let me show it to you how the mask method works.
mpg['mpg'].mask(mpg['mpg'] < 20, 'Less than Twenty' )
With a mask method, often we pass two parameters to the method; the condition and values to replace. In this case, I give a condition where the mpg values are less than 20 then replace the values with ‘Less than Twenty’.
In case you need more than one condition, you need to chain the methods.
mpg['mpg'].mask(mpg['mpg'] < 20, 'Less than Twenty' ).mask(mpg['mpg'] > 40, 'More than Fourty')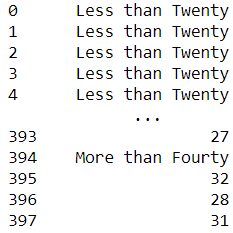
There is also a where method that works as an inverse of what mask method does.
mpg['mpg'].where(mpg['mpg'] < 20, 'More than Twenty' )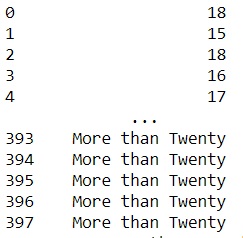
From the result, you could see that the values that did not meet the condition are the ones that have their values replaced.
In any case, you could replace the values with the method you comfortable working with.
3. Hiding Index and/or columns you did not need
There would be a time where you want to present your Data Frame, and you did not want the content to distract the audience (often happens to me, especially the index values).
For example, I want to show you the top five of the mpg dataset.
mpg.head()
The result above shown us the whole table, with the index present in the table. There is a time I present a table just like above and was asked about the number beside the table and need time to explain it to everybody. This is certainly a waste of time. That is why we could try to hide the index with the following code.
mpg.head().style.hide_index()
We could use the style.hide_index() method from the Data Frame object.
Furthermore, there might be a case that you might want to left out only one column and present the rest of the Data Frame. It would be a lot of work to select every column you want to just left out one unnecessary column.
In this case, we could use the style.hide_columns() from the Data Frame object. Let’s see the example below.
mpg.head().style.hide_index().hide_columns(['weight'])
In my example above, I want to left out the weight columns, so that is why I only pass the weight in the method. Of course, you can hide as many columns as you want. You just need to pass the values into the list.
Conclusion
In this article, I have shown you three tricks to simplify your daily data work with Pandas. This includes:
Using query
Replacing values with replace, mask, and where
Hiding with hide_index and hide_columns
I hope it helps!