
3 Primary Methods for Pandas Data Selection You Should Know
Select your data in the way you need it

Select your data in the way you need it

Pandas is an inseparable library as a Data Scientist, especially for Pythonist. This is because of the library capability for storing and manipulate data with ease. One example of the Pandas library power is how easily we can select the data we want. Let me give you an example with mpg dataset from the seaborn library below.
#importing the libraryimport pandas as pdimport seaborn as snsmpg = sns.load_dataset('mpg')mpg.head()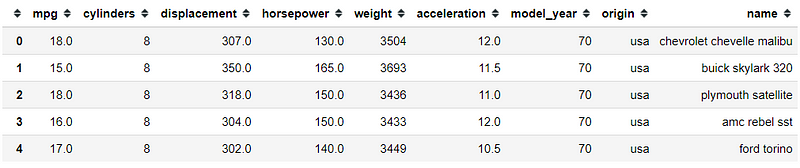
This is our mpg dataset in data frame form. Now, let’s say that I only want the mpg column, we could just get it with the following code.
#Getting the data column with bracket and the column namempg['mpg'].head()
We ended up with the series data of the column we select previously. Now, this is just the example of selecting data. In the next section, I would show four different main methods for selecting data using Pandas.
“Pandas is an inseparable library as a Data Scientist, especially for Pythonist.”
1. Selection by Label
Taken out from the Pandas Documentation.
“pandas provides a suite of methods in order to have purely label based indexing. This is a strict inclusion based protocol. Every label asked for must be in the index, or a
KeyErrorwill be raised.”
Pandas provide us to selecting the data based on the label. If you realise, in our previous example, we only selecting the data based on the column. For selection based on the label, we need Pandas.loc attribute. Let’s show how it works in the example below.
#Selecting data on index 0mpg.loc[0]
Using .loc attribute, we select the label 0 data and ended up with the series from the label 0 row. Now, if we want to include more label in our selection, we need to select a sequence of labels with : symbol like below.
#Selecting data from index 0 to 4mpg.loc[0:4]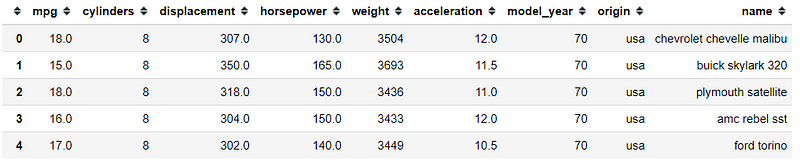
and let’s say I only want to select a certain label from various rows, I need to put in in the list object.
#Selecting data from index 0,4,6mpg.loc[[0,4,6]]
We also could add which column we want to select in the .loc attribute like below.
#Select the column we want with the list of the columns namempg.loc[[0,4,6], ['mpg', 'cylinders', 'origin']]
In a Pandas object, the first position is the row position and the second is the column position. That is why when we selecting the data, we select it based on the row first then the columns.
Our data frame would have the default label most of the time, but we could set another column as the label and selecting the data based on the new index. I would show it in the example below.
#Set the 'origin' column as the new index using .set_index then selecting the data using .locmpg.set_index('origin').loc['europe']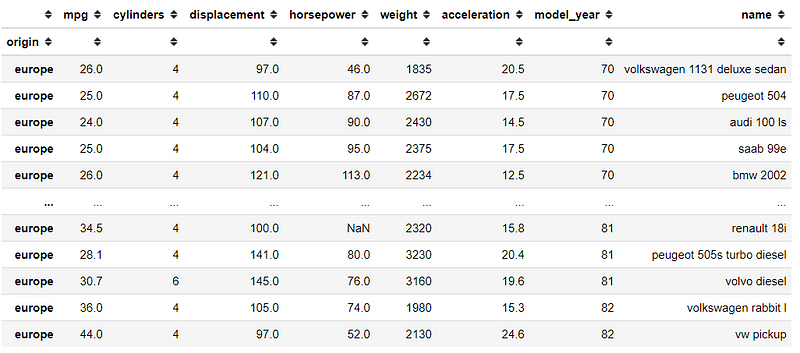
In the data frame above, now I only get the data with ‘europe’ label.
2. Selection by Position
If in the previous section we selecting the data based on the label, Pandas also provides a method for selection based on integer index position. The Pandas attribute we would use is the .iloc attribute.
These are
0-basedindexing. When slicing, the start bound is included, while the upper bound is excluded. Trying to use a non-integer, even a valid label will raise anIndexError.
Above is the official Pandas documentation explanation. We could see from the explanation is that when we selecting the data, we only use the integer value for the 0-based position and not the label. Let me show it in the example below.
#Selecting the data in the index position twompg.iloc[2]We get the series from the data frame in position index position two. In a glance, there is no difference compared to when we use the label method but how if we change the label as non-integer label.
mpg.set_index('origin').iloc['europe']
It would raise an error now because using .iloc attribute is based on the position, not the label itself. Now, what would happen if with the same data as above but I select the data by using an integer value?
mpg.set_index('origin').iloc[2]
We could see that the result is similar if we did not change the index at all. It is because we select the data based on the position, not the label. Now, how about a sequence index like in the previous section? would it still work?
#Selecting a sequence index based on positionmpg.iloc[0:4]
Yes, we could still select the based on the sequence but what we need to remember is that in the position based selection the lower bound is not included. We select 0:4 but we only end up with the data from position 0 to 3.
Just like before, we could also select a specific position by using a list object.
mpg.iloc[[0,4,6]]
but, if we want to include columns selection here.
mpg.iloc[[0,4,6], ['mpg', 'cylinders', 'origin']]
An error would raise because .iloc function only accepting numeric index, nothing else.
3. Selection by Boolean
Before we continuing our discussion, I want to explain how Pandas could have Boolean as their result. Just try this following code.
#Comparing the 'mpg' data with integer 17mpg['mpg'] > 17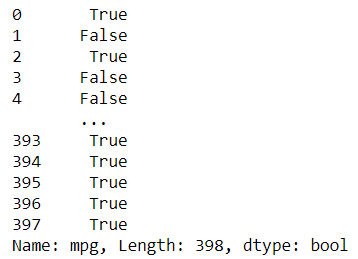
The result would be a series with Boolean values which indicate the result status. True would be the data with a number higher than 17 and False is below than 17. Now, we could put the Boolean value as the selection criteria. Let’s try the following code.
#Inputing the criteria within the square bracketmpg[mpg['mpg'] > 17]
The result would be all the data where the ‘mpg’ data is above 17 or every single True Boolean result. What if we want to have two or more criteria? We could also do that just like the following code.
mpg[(mpg['mpg'] > 17) & (mpg['origin'] == 'japan')|~(mpg['horsepower'] <120)]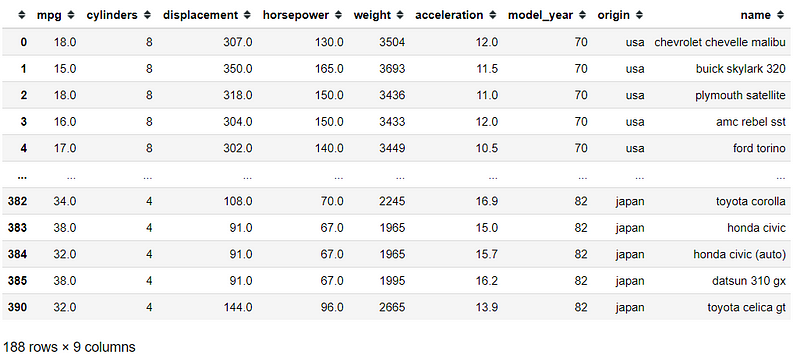
In the above code, I specify three criteria; ‘mpg’ data above 17, ‘origin’ data equal to japan, and ‘horsepower’ data not below 120. When we put more than one criteria, we need to put it in the bracket. Moreover, we using & symbol as and, | symbol as or, and ~ symbol as not.
Conclusion
Here I have shown you how to select data based on the label, position, and boolean. While there are many ways of selecting data, just use the method you feel more familiar.