
[3/5] Statistic for Business Technique: Monte Carlo Simulation Analysis
The third part of the email course series regarding Statistic for Business Technique


Hello all! This is the third part of the Statistic for Business Technique Email Course I have started recently. This course intended to give knowledge regarding the statistic technique people could use to analyzing data that the business people understand. If you miss the first and second parts, you could check out the course below.

In the third part of the course, I introduce you to a statistical technique often used in Monte Carlo Simulation Analysis. Let’s get into it.
Monte Carlo Simulation Analysis
What is Monte Carlo Simulation Analysis? It is a technique used to understand the possible event outcome with uncertainty. The Monte Carlo Method was invented by John von Neumann and Stanislaw Ulam, named after Monaco's well-known casino town.
Monte Carlo Analysis is used in many business industries to assess the risk, such as stock prediction, machine learning model, forecasting, and many more. Many businesses prefer to use the Monte Carlo analysis because it offers understandable insights to non-technical people and confidently providing a value interval with their problem business. That is why learning Monte Carlo Analysis would be valuable for your skillset.
How is Monte Carlo Simulation Analysis works? In a high-level, Monte Carlo analysis is done by running the experiment multiple times, and we summarize the result to acquire the estimated range value from the existing model.
The simplest Monte Carlo approach is the flip the coin experiment. Let me set up the experiment using Python. I would use the Numpy package to produce a random number, assuming that 0 is head and 1 is tail. Let’s see what the probability is if we run the experiment 1 time.
import numpy as np
import seaborn as sns
coin = []
for i in range(1):
coin.append(np.random.randint(0,2))
plt.title('Coin Flip Count')
sns.countplot(coin)

The result is exactly only one flip occurrence, and the probability would be 100%. However, we know that coins have two sides, and a one-time experiment would not be an accurate estimation. Let’s repeat it with 10 repetitions.

The result is now closer to the expected probability, which is 50%. Let’s rerun it with higher repetition—say, 1000.

The result becomes even closer to 50%. If we keep running the experiment, then it would achieve the expected probability. We don’t need to run more experiments as the diminishing return would only happen (a higher number of experiments only yield a similar result to the lower one).
Above is how we did the Monte Carlo analysis. However, the technique involves more detailed requirements. Which are:
Setting up the Statistical Equation or the Prediction Model. We need to have both the independent and dependent variables for our model. However, it also works if you only want to samples the dependent.
Determine the probability distributions of the independent variables to estimate the likely values for the repetition.
Run the simulation experiment continuously and independently by generating random values of the independent variable. The repetition could be run as much as you want.
Monte Carlo Analysis Application
Let’s use how the application of Monte Carlo in the financial industry using Python. There is one article that explains the application really well here; you might want to read it.
I would give an overall quick application example that could help you understand. Let’s say you have daily house sales data in various years, and you want to know the possible estimation of the yearly revenue in the next year. In this case, we could take the average of the data and assumes the probability distribution.
Let’s say that the data average is $15000, and the Standard Deviation is $270. We then try to simulate samples of the data from the Normal Distribution. Let’s try 10 at first.
sns.distplot(np.random.normal(15000, 270, 10).round(2))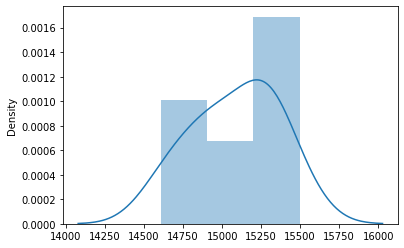
The result of 10 experiments sampling shows the result is between 14600 to 15500. We could try to add more repetition; this time, let’s use 1000.
sns.distplot(np.random.normal(15000, 270, 1000).round(2))
The estimation is much wider, put it closer to the normal distribution. Let’s try 10000 experiments.
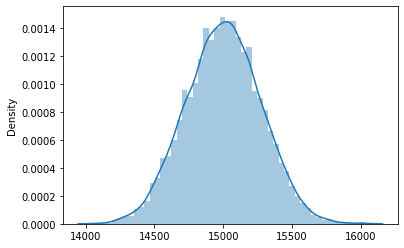
Right now, we could estimate that next year's yearly revenue would amount between $14500 to $15500. With this estimation, you could tell the business that with the current strategy and model, this is what we would yield.
That is all for the Third part! Let’s learn again in the next part. Thank you.