
7 LLM Generation Parameters To Know - NBD Lite #11
Several hyperparameters to influence the text generation result

If you are interested in more audio explanations, you can listen to the article in the AI-Generated Podcast by NotebookLM!👇👇👇
Text generation using LLM (Large Language Model) has become a tool that helps many businesses.
Models such as GPT, LLaMa, Mistral, and many others have been helpful for any downstream tasks.
Fine-tuning the LLM has become the gold standard for business needs. Still, there are a few ways to fine-tune the text generation process, one of which is using the generation hyperparameter.
Adjusting the hyperparameters could help you tailor the model’s output, so it’s good to know several of these hyperparameters. We will explore them soon!

Word From Sponsor
Get immediate access to up to 8 NVIDIA® GPUs, along with CPU resources, storage, and additional services through our user-friendly self-service console.
Learn more at Nebius.ai.

1. max_tokens
The first hyperparameter we would explore is the max_tokens. It’s a hyperparameter that would set a limit on the tokens produced by the model.
It’s useful to control the text output length and ensure it doesn’t exceed the intended size.
For example, if max_tokens=100, the model generates up to 100 tokens before stopping,
It’s useful when the tasks need shorter tokens, such as text summaries. Also, longer tokens might cost more, so we want to limit the output token.
2. Temperature
The Temperature hyperparameter controls the randomness of the token selection during text generation. It’s made possible by adjusting the possible next token probability distribution.

A higher temperature means the model is much more diverse, and a lower means it is more deterministic.
For example, setting temperature=0.1 will make the output more predictable while temperature=1.5 will make the text generation much more diverse.
3. top_p (nucleus sampling)
The top_p or nucleus sampling is a generation hyperparameter that adjusts the next token generation using the probability distribution.
The token that would be generated is the most probable token where cumulative probability equals p.
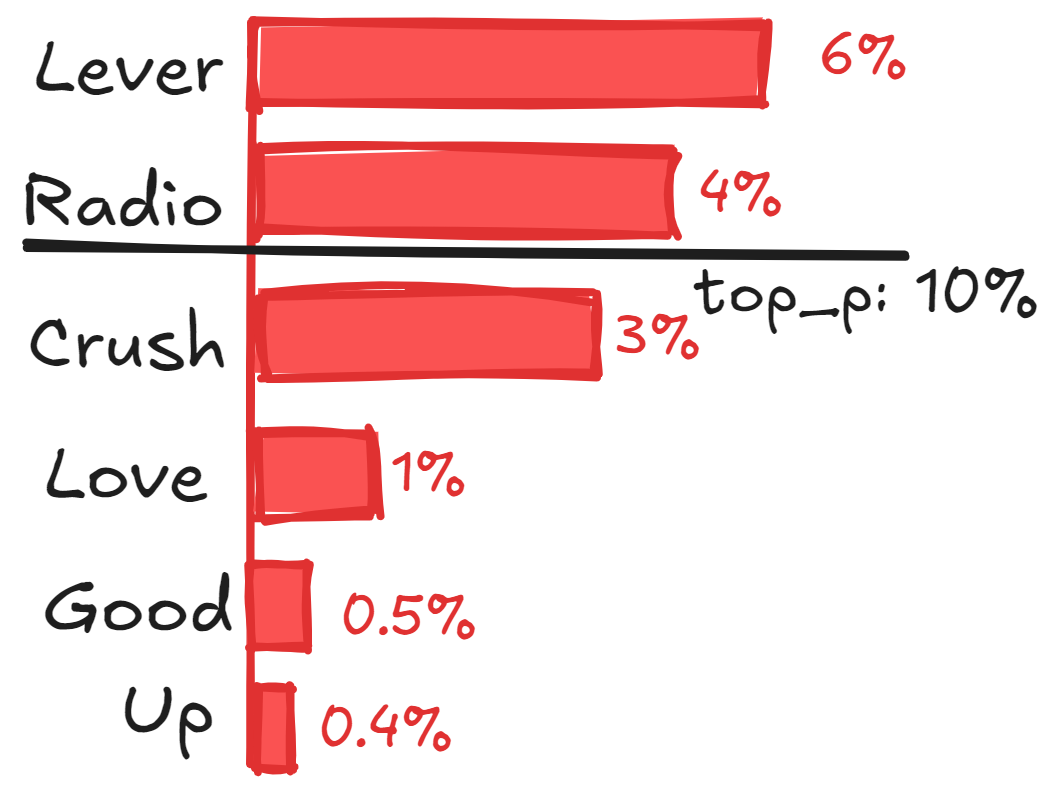
For example, if top_p=0.1, the model will choose from tokens whose combined probability adds up to 10%, ignoring the rest. It would minimize the diverse text generation that happens.
4. top_k
The top_k hyperparameter works similarly to the top_p, but it restricts the sampling pool using absolute numbers instead of cumulative probabilities.
It would ensure that only the highest probability tokens were considered during text generation.

For example, top_k=50 means the model would only sample from the top 50 tokens (by probability), regardless of their cumulative probability.
Higher values would mean diverse results and vice versa.
5. frequency_penalty
The frequency_penalty hyperparameter would penalize the model that generates repetitive tokens too frequently. It’s a way to reduce repetition tokens.
A positive value would discourage many repetitions and use much more diverse tokens. The negative value would be the other way.
For example, frequency_penalty=2 would highly discourage the repetition of tokens.
6. presence_penalty
The presence_penalty hyperparameter would encourage the generation of new tokens that haven’t appeared yet.
It has an intention that similar to the frequency_penalty but in a different direction.
Positive values of the presence_penalty increase the likelihood of introducing unused tokens in the generated text.
For example, presence_penalty=2 would strongly encourage the model to avoid using the same token multiple times.
7. stop
The stop hyperparameter would accept a list of tokens that become a signal to stop further text generation.
It means that when the model selects a certain token, the whole process of text generation comes to an end.
It’s useful when we need to stop the model from generating any unnecessary or irrelevant text.
For example, If stop=["\n"], the model will stop generating once a new line character is encountered.
That’s all for today! I hope this helps you understand a few generation hyperparameters to improve your LLM text generation.
Are there any more things you would love to discuss? Let’s talk about it together!
👇👇👇
FREE Learning Material for you❤️