
8 Advance Feature Engineering For Machine Learning - NBD Lite #10
Improve your predictive performance with these features

If you are interested in more audio explanations, you can listen to the article in the AI-Generated Podcast by NotebookLM!👇👇👇
In my professional experience, there have been many times when I have the features, but the model performance is just subpar.
That is only being improved when I perform feature engineering.
Feature engineering is transforming our data into something more meaningful for the model.
Practical feature engineering can improve model performance by capturing essential patterns, which increases the model's predictive power.
There are many feature engineering techniques we can use. Here are 8 advanced techniques you should know!

1. Polynomial Features
The polynomial feature is a feature engineering technique that generates new features by raising existing features to powers, which allows for the interaction of terms between features.
For example, given two features, x1 and x2, polynomial features could generate x1^2, x2^2, and x1*x2.

This technique allows linear models to fit into nonlinear data; thus, it becomes valuable when there is a nonlinear relationship between features and targets.
Although it can introduce overfitting, we must be careful when using it.
from sklearn.preprocessing import PolynomialFeatures
import numpy as np
X = np.array([[2, 3], [3, 4], [5, 6]])
poly = PolynomialFeatures(degree=2)
X_poly = poly.fit_transform(X)2. Target Encoding
Target encoding is a categorical encoding process that replaces the category value with the statistic (e.g., mean) of the target variable for each value.
It’s a valuable technique when we have a high-cardinal (dimension) variable, and one-hot encoding would introduce the curse of dimensionality.
However, we must be careful when using the technique, as it could also cause data leakage, mainly if we use it on the entire dataset. So, the method is better when performing cross-validation or on the training data.
import pandas as pd
from category_encoders import TargetEncoder
data = {'category': ['Apple', 'Apple', 'Orange', 'Orange'],
'target': [0, 1, 1, 0]}
df = pd.DataFrame(data)
encoder = TargetEncoder(cols=['category'])
df_encoded = encoder.fit_transform(df['category'], df['target'])3. Feature Hashing
Feature hashing is a feature engineering technique for categorical encoding. It converts category values into numerical values using a hashing function.
The technique is beneficial because we can compress categories into our intended fixed number of columns, which is more efficient than the one-hot encoding.
However, feature hashing can cause a phenomenon we call a collision. Different categories are hashed to the same value in this event, introducing noise to the dataset.

from sklearn.feature_extraction import FeatureHasher
data = [{'category': 'A'}, {'category': 'B'}, {'category': 'A'}, {'category': 'C'}]
hasher = FeatureHasher(n_features=5, input_type='dict')
hashed_features = hasher.transform(data).toarray()4. Lag Features
Lag features are a unique feature engineering technique for time-series datasets. It introduces past values of variables as new features.
The main benefit of using the lag features is that they capture temporal dependencies, which makes them helpful in forecasting tasks.
However, we must be careful when choosing the lag period, as it could introduce multicollinearity, which could decrease the model's performance.

import pandas as pd
data = {'date': pd.date_range(start='2022-01-01', periods=6, freq='D'),
'sales': [100, 110, 120, 130, 140, 150]}
df = pd.DataFrame(data)
df['lag1'] = df['sales'].shift(1)
5. Binning
Binning is a feature engineering technique for transforming continuous numerical values into discrete categories or bins. For example, salary can be binned into ranges (100-500, 501-1000, etc.).
It’s a useful technique for simplifying complex data and allowing for more interpretation of the feature relationship. It also helps to handle noisy and outlier data.
However, simplification also could result in loss of information, especially if the continuous variable has a strong linear relationship with the target variable.
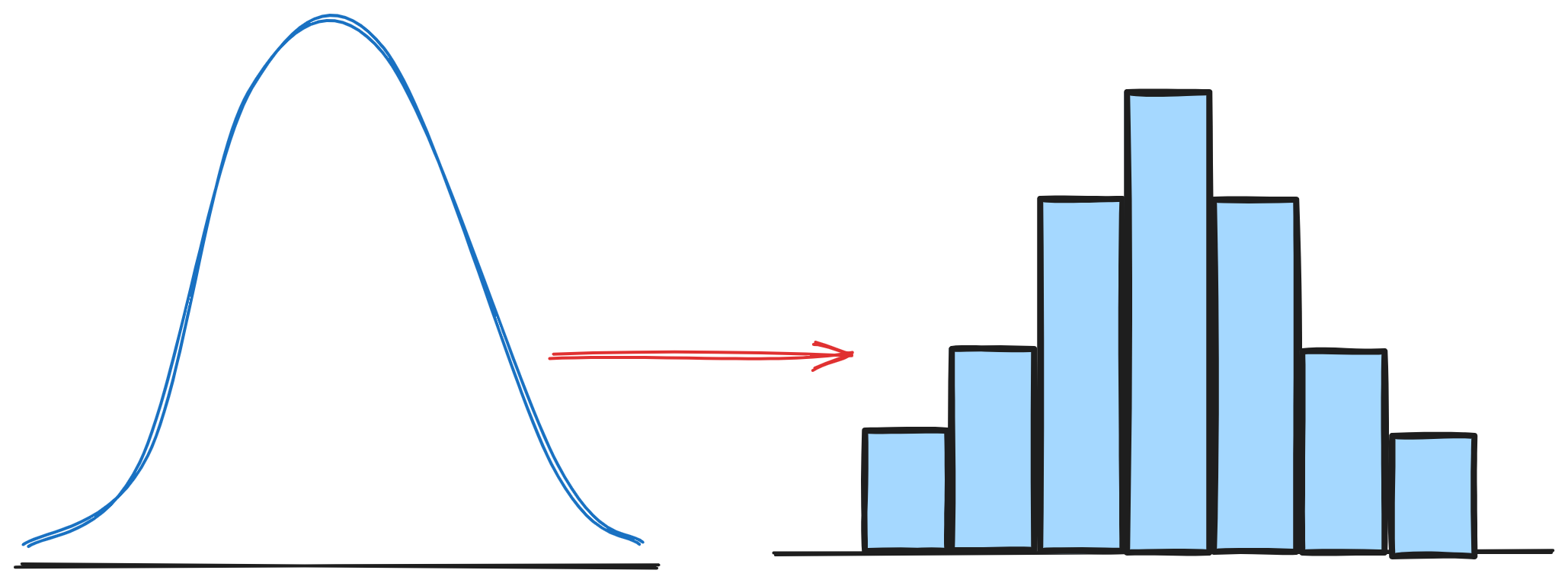
import pandas as pd
data = {'age': [25, 45, 18, 33, 50, 70]}
df = pd.DataFrame(data)
df['age_group'] = pd.cut(df['age'], bins=[0, 18, 35, 60, 100], labels=['child', 'young adult', 'middle-aged', 'senior'])6. Feature Interactions
One of the most vital techniques in feature engineering is creating a new feature by combining two or more existing features.
We can add, multiply, divide, or do anything else that captures the interaction of the features together. We want the interaction effect as it might be something that individual features can’t detect.
Feature interactions increase the model's performance, but not every interaction is meaningful. We also need to consider the domain subject when creating the interaction, as sometimes it’s just not meaningful in the business.
df['interaction'] = df['feature1'] * df['feature2']7. Dimensionality Reduction
Dimensionality reduction is a feature engineering technique that reduces the number of features by transforming them into smaller sets of data. Examples of algorithms for this technique are Principal Component Analysis (PCA) and Singular Value Decomposition (SVD).
The technique helps speed up training time and decrease overfitting risks.
However, choosing the right number to keep could be subjective and require experiments to determine whether the technique would improve the model's performance.
from sklearn.decomposition import PCA
import numpy as np
X = np.array([[2, 3], [3, 4], [5, 6], [6, 7]])
pca = PCA(n_components=1)
X_reduced = pca.fit_transform(X)8. Group Aggregation
Group aggregation is a feature engineering technique for computing summary statistics for groups in the dataset.
It’s helpful to capture patterns at a higher level and improve model performance by providing insight that is much more valuable than individual data point levels.
However, group aggregation might also require domain knowledge, and not every piece of information would be meaningful. You might also need to experiment to see if the result can help increase your model performance.
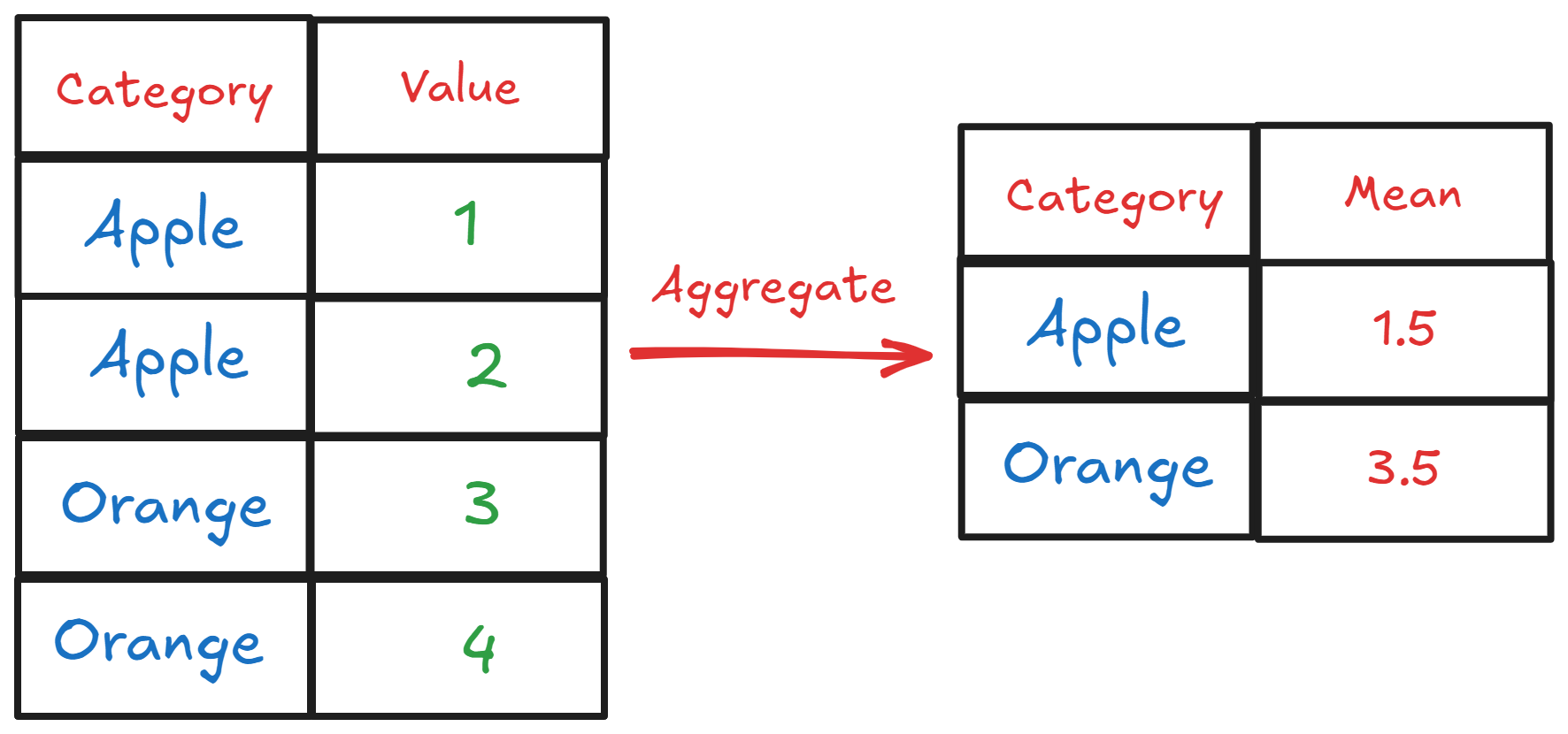
df.groupby('category').agg({'transaction_amount': ['mean', 'sum']})That’s all for today! I hope this helps you understand a few feature engineering techniques for your machine-learning model!
Are there any more things you would love to discuss? Let’s talk about it together!
👇👇👇
FREE Learning Material for you❤️
👉Top Python Packages for Feature Engineering