
Accelerate Complicated Statistical Test for Data Scientist with Pingouin
Quick and easy important statistical test in one package

Quick and easy important statistical test in one package

As a Data Scientist, our work consists of creating a Machine Learning model and building our assumption regarding the data.
Knowing how our data related and any differences between the target statistic could make a big difference in our data analysis and model creation.
I really encourage you to learn basic statistics and hypothesis testing if you want to edge in the data science field.
Regardless of your knowledge in statistic testing, I want to introduce an interesting open-source statistical package that I know would be useful in your daily data science work (because it helps me)—this package is called Pingoiun.
Let’s see what this package offer is and how it could contribute to our work.
Pingouin
According to the Pingouin homepage, this package is designed for users who want simple yet exhaustive stats functions.
It was designed like that because some function, just like the t-test from the SciPy, returns only the T-value and the p-value when sometimes we want more explanation regarding the data.
In the Pingouin package, the calculation is taken a few steps above. For example, instead of returning only the T-value and p-value, the t-test from Pingouin also return the degrees of freedom, the effect size (Cohen’s d), the 95% confidence intervals of the difference in means, the statistical power, and the Bayes Factor (BF10) of the test.
Let’s try the package with a real dataset. For starter, let’s install the Pingouin package.
#Installing via pippip install pingouin#or using condaconda install -c conda-forge pingouinNow, let’s say I have the car mpg dataset from various places (available free from the Seaborn package).
import seaborn as snsmpg = sns.load_dataset('mpg')
With this dataset, I might have a question. Are there any mpg differences between cars from different origins? (The origin unique categories are ‘usa,’ ‘europe,’ and ‘japan’).
With the question above, I already try to assume that there is a difference in the dependent variable with different treatments (the car’s origin) (mpg). This is a typical hypothesis question.
We know we need to select which statistical testing is valid to test our assumptions with a question in mind. For the sake of the example, we would use One-way ANOVA testing, which is hypothesis testing used to analyze the differences among group means in a sample. It is used when the data you want to test have more than two treatments.
I would not explain it in detail because this article's purposes are to introduce you to the Pingouin package; in fact, we might violate some assumptions.
First thing first, I want to check if the individual sample data are following normal distribution or not (Normality Test). We can use Pingouin with the following code.
import pingouin as pgpg.normality(mpg, dv = 'mpg', group = 'origin')
By default, the normality test would use the Shapiro-Wilk test with alpha level 0.05. You can read more about that, but what is important here is that not every treatment (origin) is following the normal distribution. The ‘usa’ and ‘europe’ data are not following a normal distribution.
On the Pingouin homepage, they have provided us with the guidelines to use some testing package. One of them is for One-way ANOVA testing.
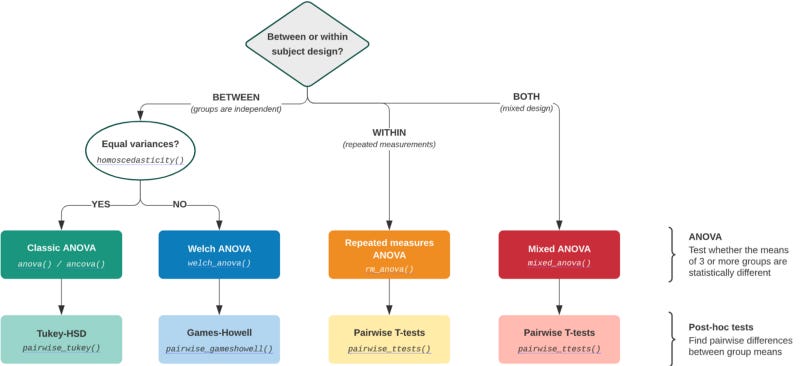
From the guide above, our test is between the groups because the data are independent. That is why we need to check the variance equality using Pingouin.
pg.homoscedasticity(data = mpg, dv = 'mpg', group = 'origin')
The default variance testing is using the Levene test, which is robust against the deviation of normality. From the testing, we can see that the data have equal variance. We could then proceed with classic ANOVA testing.
pg.anova(data = mpg, dv = 'mpg', between = 'origin')
As usual, we would like to see the p-value as guidance for us to reject the null hypothesis or not. The p-value from the function above is p-unc, which is the uncorrected p-value.
From the result above, if we assume the alpha level 0.05, we can reject the Null Hypothesis, which means there are differences between the origin treatment and the car’s mpg.
If you want to know which individual group were different, we can do the post-hoc test.
pg.pairwise_tukey(data = mpg, dv = 'mpg', between = 'origin' )
From the above post-hoc test, we use the p-tukey as the p-value. From the result above, we can see that every single individual origin is different from each other.
This means there is evidence that there are differences in the mpg between cars produced in the USA, Japan, and Europe.
That is an example of Statistical Testing using the Pingouin package; there are still many more statistical testing you could use that you could see here.
Conclusion
Pingouin is a simple yet exhaustive statistical package designed to simplify your Statistical analysis. Using a one-liner, it could produce strong information about the data you could use to analyze or create a prediction model.