
Automated Machine Learning (AutoML) Gentle Introduction — TPOT module case
The introduction to the Automated Machine Learning module

The introduction to the Automated Machine Learning module

Automated Machine Learning or AutoML according to Wikipedia is the process of automating the process of applying machine learning to real-world problems. AutoML intended to produce a complete pipeline from raw data into the deployable machine learning model. In a simpler term, AutoML capable to automatically create a machine learning model without prior knowledge of the model previously. AutoML itself is still one of the most sought of in the Artificial Intelligence field.
Until 2019 or recently, AutoML is in the peak of people’s expectations of Artificial Intelligence. For whatever reasons that make people hype about AutoML, it could not be denied that this AutoML would quite change how people work in the Data Science field. As a data scientist, I also applying AutoML in my everyday work.
AutoML is the future but it is not like it does not have any downside to it. Few things I take note about AutoML are:
It would not replace the work of data scientists. We as human after all the ones who decide which result is viable to be produced and deployed.
Data is still the most important thing. You could throw any raw data into the model, but without any preprocessing or further knowledge about the data; no good result would be present.
The prediction metric is the only aim. In the data science job, the prediction model is not necessarily the only thing we want. Most of the time, what we want is an explanation from the model about the data. If you aim to know what features are the most important, then AutoML is not the way to go.
With some downside, AutoML is still a breakthrough in the Data Science field and it is a given as a Data Scientist to learn about it. In this article, I want to give an introduction of how to implement AutoML and one of the AutoML modules; TPOT.
TPOT

TPOT is a Python AutoML module that optimizes machine learning pipelines. It will intelligently explore thousands of possible pipelines to find the best one for your data and once it finished searching (or you get tired of waiting), it provides you with the Python code for the best pipeline it found so you can tinker with the pipeline from there. Most of the python code explored in TPOT is based on the Python module Scikit-learn (not limited, but most of it) which most people work in ML with Python would familiar with.
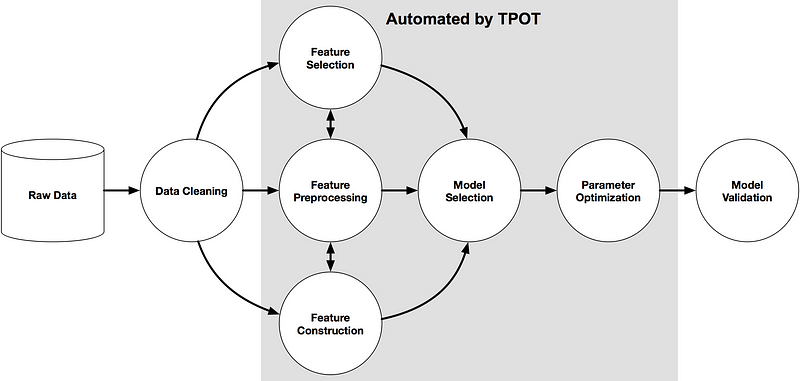
The exploration process is based on genetic programming. According to Wikipedia, It is a technique of evolving programs where we start from the population of unfit (usually random) programs, fit for a particular task by applying operations analogous to natural genetic processes to the population of programs. In a simpler term, it starts from a random ML model and by a random process of selecting the model (and the parameter), it would go to the direction of the best model. There are many technical biological terms in the parameter used by TPOT but I would explain some of the important parameters to use later.
TPOT are both used for classification and regression problems, basically, a supervised learning problem where we need target data to be predicted. Let’s try using TPOT with an example.
TPOT Example
For learning purposes, I would use the Heart Disease dataset I acquire from Kaggle. The snapshot of the data is shown below.
import pandas as pdheart = pd.read_csv('heart.csv')heart.head()
You could read the explanation of each column in the source, but this dataset is dealing with a classification problem; whether someone had heart disease or not. I would not do any data preprocessing as my intention is just to give an example of how TPOT works.
To start we need to install the module first. The recommendation to use TPOT is to use Anaconda Distribution of Python as many of the necessary modules are pre-existing there. We then install the module through pip or conda.
#Using pippip install tpot#or if you prefer condaconda install -c conda-forge tpotNow we are ready to try our AutoML using the TPOT module. Let’s import all the modules and prepares the data we would use.
#Import the TPOT specific for classification problemfrom tpot import TPOTClassifier#We use the train_test_split to divide the data into the training data and the testing datafrom sklearn.model_selection import train_test_split#Dividing the data. I take 20% of the data as test data and set the random_state for repeatabilityX_train, X_test, y_train, y_test = train_test_split(heart.drop('target', axis = 1), heart['target'], test_size = 0.2, random_state = 101)All the preparation is set, now let’s try using AutoML by TPOT for the classification problem.
tpot = TPOTClassifier(generations=100, population_size=100, offspring_size=None, scoring='accuracy', max_time_mins=None, max_eval_time_mins=5, random_state=101, warm_start=True, early_stop=20, verbosity=2)It seems there are many parameters in this classifier, and yes it is. You could check all the parameter exist in the TPOTClassifier here but I would explain some of the important parameters below:
generations control the number of iterations to the run pipeline optimization process.
population_size control the number of individuals to retain in the genetic programming population every generation.
offspring_size control the number of offspring to produce in each genetic programming generation. By default, it is equal to the size of the generations.
In total, TPOT will evaluate population_size + generations × offspring_size pipelines. So, above we would have 100 + 100 × 100 which equals 10100 pipelines to evaluate.
Other important parameters are:
scoring control function used to evaluate the quality of a given pipeline for the classification problem. See the scoring function here for the scoring function that could be used.
max_time_mins control how many minutes TPOT has to optimize the pipeline. If it is none, then TPOT would not have any time limit to do optimization.
max_eval_time_mins control how many minutes TPOT has to evaluate a single pipeline. Higher time means TPOT could evaluate a more complex pipeline but would take longer.
warm_start is a Flag indicating whether the TPOT instance will reuse the population from previous calls. Setting the warm_start=True can be useful for running TPOT for a short time on a dataset, checking the results, then resuming the TPOT run from where it left off.
early_stop control how many generations TPOT checks whether there is no improvement in the optimization process. If there is no more improvement after the given number, then TPOT would stop the optimization process.
From the parameter above, let’s try to fit the TPOTClassifier with our training data.
tpot.fit(X_train, y_train)The optimization process would be looks like below:
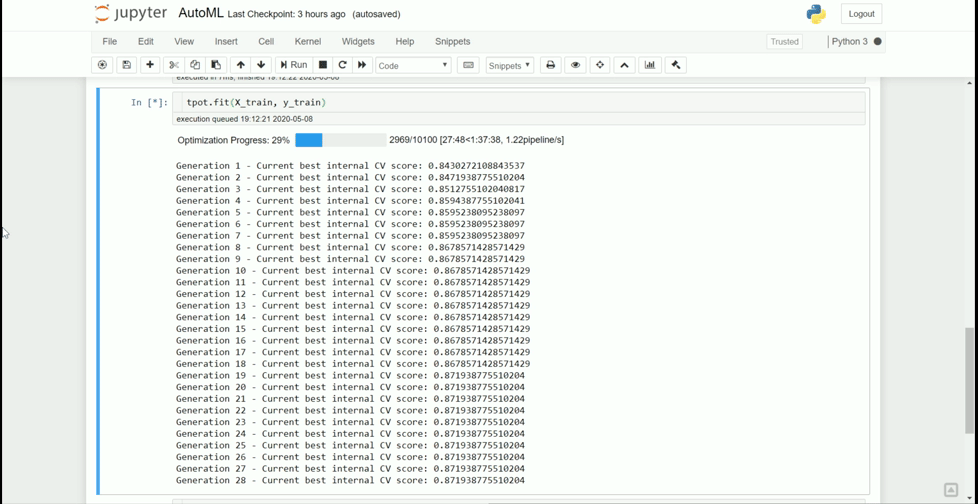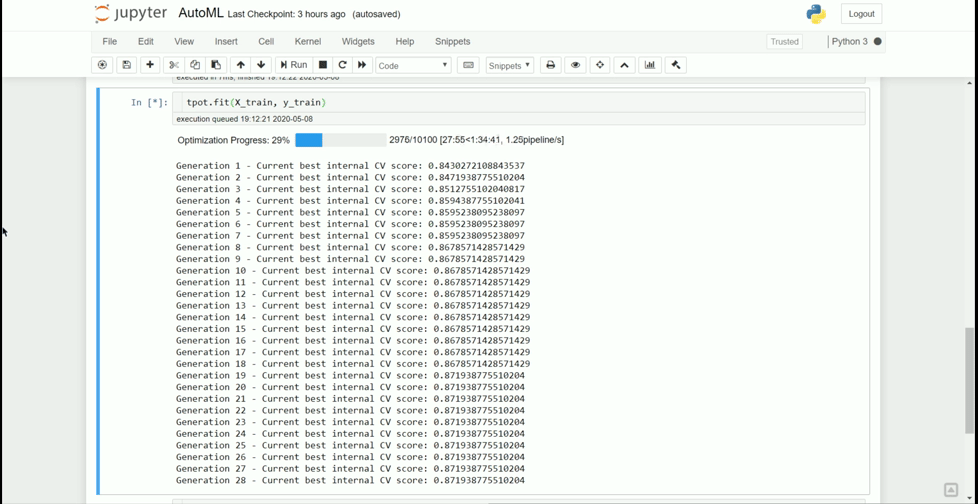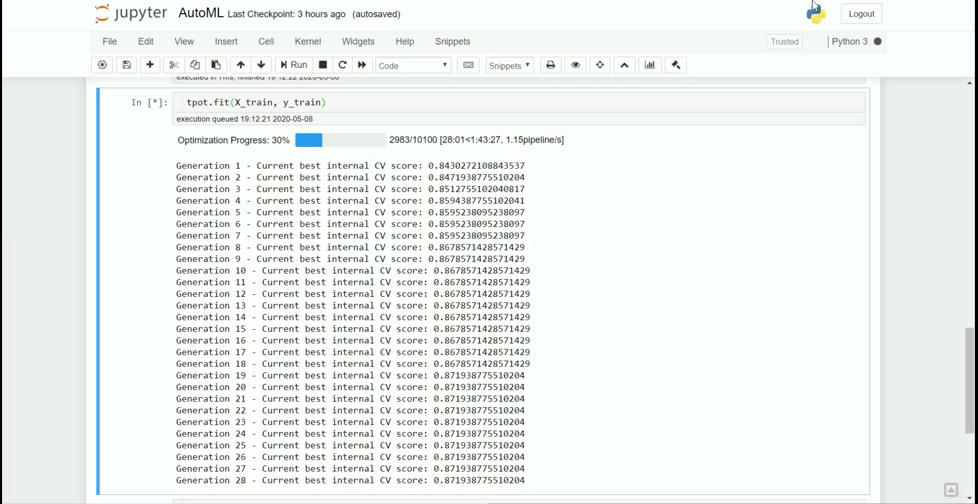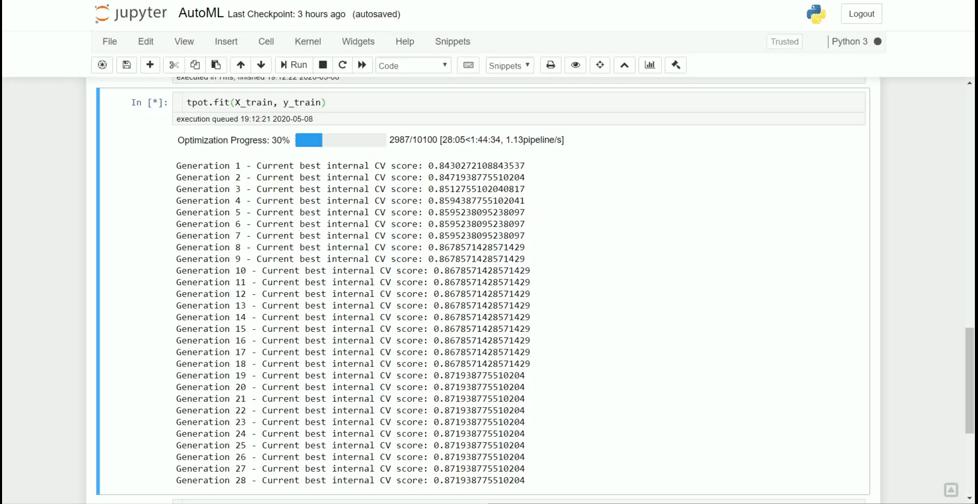
The optimization process would stop if every pipeline has been evaluated, reach the time limit, hit the early stop limit, or simply terminated. Here is what happens to the AutoML process we try before.

It seems the pipeline has reached the maximum early stop number and arrive at the best pipeline. Of course, as it is a randomized process, I could end up with a completely different model if I ran it once more.
Let’s check the model performance if we test it against the test data. We could use the optimized TPOT model to be used as a predictive model.
from sklearn.metrics import classification_reportprint(classification_report(y_test, tpot.predict(X_test)))
The model seems quite good despite no preprocessing are done although I bet we could achieve a much better model if we analyze the data but let’s leave it there.
Now, if you rather have a complete set of pipelines exported automatically, you could do it by using the following code.
#Give any name you want but still contain the .py extensiontpot.export('tpot_heart_classifier.py')The complete pipeline would show up in your folder, exactly in the folder where your notebook to work at. If you open that file, it would look like below:
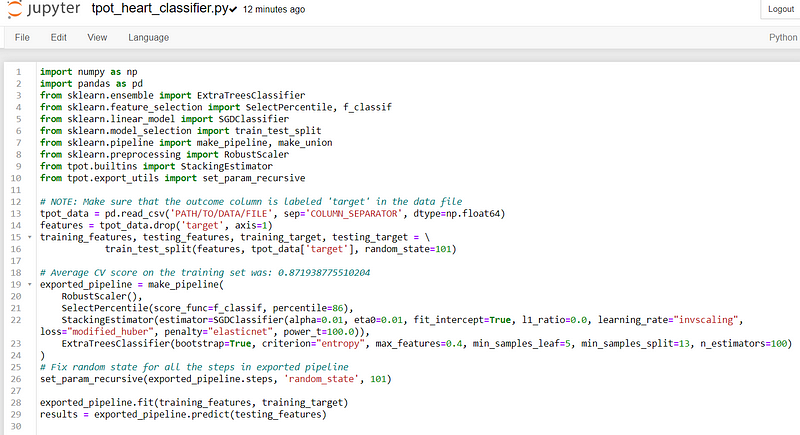
As we can see, not only we get the best pipelines but we also get a complete rundown of the process.
Conclusion
I just show you how the AutoML using TPOT is used. The process is simple and the result is not bad from the evaluation standpoint. Although, AutoML is not a tool to achieve the final result model; in fact, AutoML only serves as the beginning of the model optimization because it could pinpoint which direction for us to go.