
Breaking Down the Classification Report from Scikit-Learn - NBD Lite #6
Have you understand the classification report output?

The best model is the one that makes it into production and provides values.
However, not every model you have would give the benefit as many of them would end up with disastrous results.
How do we know the model is not good? Model Evaluation, of course.
The common way to evaluate the result is by using the classification_report function from Scikit-Learn.
It’s easy to use them; you only need to have your predictions and actual results. Then, you can pass them to the Scikit-Learn classification report to get the report like the one below.

It seems easy, but how should one read the report above? Let’s try to break it down.

We can summarize the report using the visual representation above. Let’s explore them one by one.
1. Class Name
The class that the classifier tries to predict. The report will show more names if we have more than two classes.
The class names are 0 and 1 by default, but we can change them. In the example, we assign the name as malignant and benign.
2. Metrics for Each Class Prediction
The reports show three metrics—precision, recall, and F1 score — are used to evaluate each class's performance.
Precision
Precision is the ratio of the correctly predicted class to the total predicted class.

Practically, it tries to minimize the False Positive cases that happen in the classifier.
However, positive doesn’t mean it is only specific to a certain class. The positive class means the current class it tries to predict.
The precision of 0.97 for Malignant means it calculates the precision to predict the Malignant class—which means the positive is the Malignant class. It’s also true for the Beningn class.
Recall
Recall is the ratio of correctly predicted class to all data in the actual class.

In practice, it would try to minimize the False Negative cases that happen in the classifier.
Similar to precision, it’s up to your business cases to determine which cases you want to minimize.
However, you can use the next metric to balance the false positive and negative cases.
F1 Score
F1 Score is a harmonic means between the Precision and Recall score.
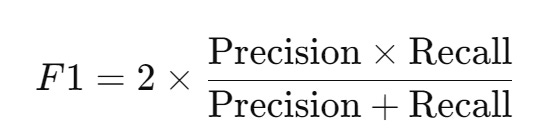
The metric would give a single number that would take account of both false positive and false negative cases.
If balance is important for certain class predictions, then you should focus on this metric.
3. Actual Instances for each class (Support)
The number of data points that belong to each class. For example, there are 63 Malignant and Benign.
The support number shows how many data points are considered for calculating the metrics for each class.
Higher support means more data points for that class, which could affect the metric reliability.
4. Accuracy score
The overall accuracy score for the classifier gives a general idea of the model's performance but can be misleading as it considers every correct prediction for both classes.

To understand the classifier's performance, we must accompany accuracy with the other metrics.
5. Metrics Average
The report has two metrics averages: Macro Average and Weighted Average.
The Macro Average is straight to the point where it takes the average of each metric for all the classes.
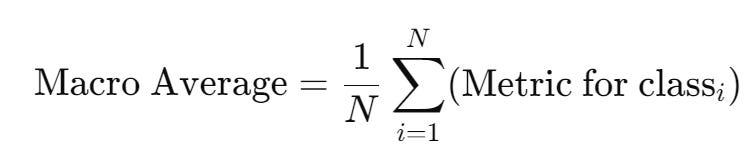
For example, the precision macro average is 0.97 because it’s calculated as:
(0.97 + 0.98)/2 = 0.975 (rounded down to 0.97)
The Weighted Average is a bit more complex as it considers the support in the calculation.
You can see the Weighted Average for precision is calculated as:
1/171 * ((0.97 * 63) + (0.98 * 108)) = 0.976 (rounded up to 0.98)
Weighted average usually is a better measurement when you have an imbalance case.
That’s all for a short reading about the Classification Report from Scikit-Learn.
I hope it is helpful for your work!
Have something that you want me to write? Write it down in the comment below
👇👇👇
FREE Learning Material for you❤️