
Comparing Model Ensembling: Bagging, Boosting, and Stacking - NBD Lite #7
Simple summary of the popular methodologies

Ensemble learning is a machine learning methodology that combines predictions from multiple models.
The method uses a weak learner model to produce the final prediction to improve the model performance.
The ensemble concept is to combine individual weaker models and collectively become a strong learner.
There are a few ensemble methods, but we would focus on the most popular and valuable:
Bagging
Boosting
Stacking
Before we start, here is a visual summarization to help you understand what we will discuss.

Bagging
Bagging or Bootstrap Aggregating is an ensemble methodology that uses multiple individual weak learning trained on different subsets of training data.
Let’s see how the Bagging Ensemble works.
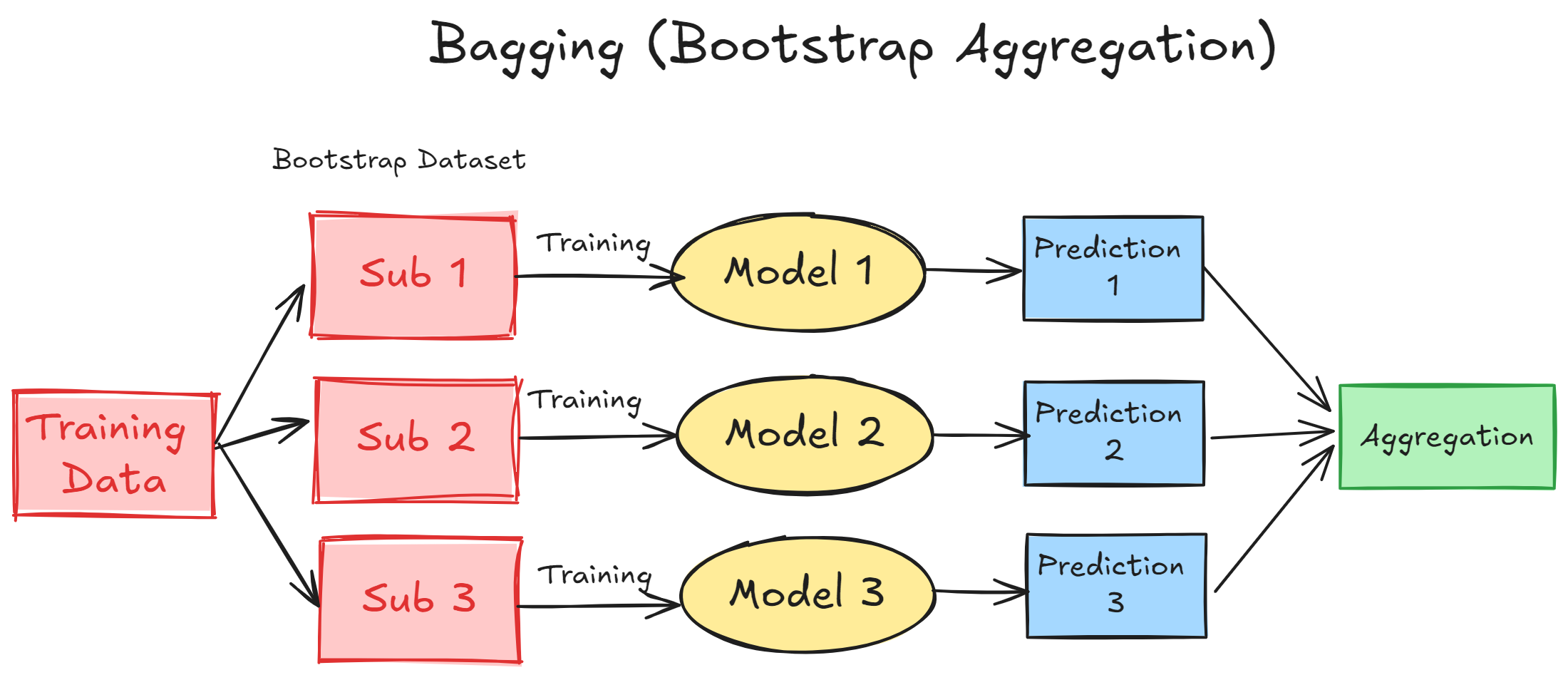
As you can see in the process, the training data becomes a subset of the original via bootstrap.
If you are unsure what a Bootstrap is, it’s a resampling statistical method with replacement. Basically, it resamples from the original data as the population and draws randomly from that population to generate a new dataset.
The amount of generated data is usually similar to the original, but you can always control it.

The table above shows how Bootstrap. The same data can be shown multiple times, and some data points are not even present in the Bootstrap dataset.
Bootstrap data aims to create diverse datasets and estimate uncertainty from them. As diversity is pivotal for the ensemble method, Bootstrap that every model sees a different subset of data.
By using bootstrap, bagging model would essentially be able to reduce bias and increase model robustness against overfitting.
The Bagging Model example is the Random Forests model. It’s a popular ensemble method that uses bagging with decision trees, adding an extra layer of randomness by selecting a random subset of features at each split.
The final prediction for the Bagging model usually uses the average for the regression case and the majority voting class for the classification case.
Conceptually, the Python code implementation is shown in the image below.

Boosting
Unlike bagging, Boosting didn’t train the model in parallel; instead, it opted for a sequential process.

Conceptually, the Boosting process would train the entire dataset to the model and iteratively perform error correction based on the previous model.
The main idea is to focus on the data points the previous model could not predict.
By assigning weights to both the model and the weak learner, Boosting would adjust the attention to misclassified data points and adapt the model weight to reflect its accuracy contribution to the final model.
The prediction result is not aggregated in the end. Instead, the final prediction is aggregated at each step. The model prediction can be summarized in the following equation.

Using the weighted average, the higher weight (α) would influence the result much more.
For the Python implementation, you can use the following code.

Stacking
Stacking is different from Bagging and Boosting, which typically focus on using one model type.
In the Stacking methodology, they try to incorporate multiple different types of models (base model/level-0 model) to improve the model's performance.

Stacking would leverage all the various model strengths by training the Meta model (level-1 model) to combine their prediction.
The process is simple: we split up the data, and then set up different types of base models for training.

Then, each base model provides predictions for training the meta-model, which could be any model, even the one you used in the base model.
However, selecting the meta-model might require an experiment to determine which performs best. What is important is that the meta-model can capture the whole pattern from the generated training data.
Here is an example dataset generated by stacking for the spam classification problem.

And here is the Python implementation.

That’s all for today! I hope this helps you understand how each popular ensemble learning method works conceptually.
Are there any more things you would love to discuss? Let’s talk about it together!
👇👇👇
FREE Learning Material for you❤️