Easy Document Preparations for Gen AI Ecosystem
Preparation is already half the battle.

I’m sure that many of you are already familiar with products like ChatGPT or DeepSeek these days. With just a prompt and some documents, you quickly get a result.
However, business use cases often demand more than what standard model implementations offer. That’s where advanced techniques—such as fine-tuning, retrieval-augmented generation (RAG), agents, and more—come into play.
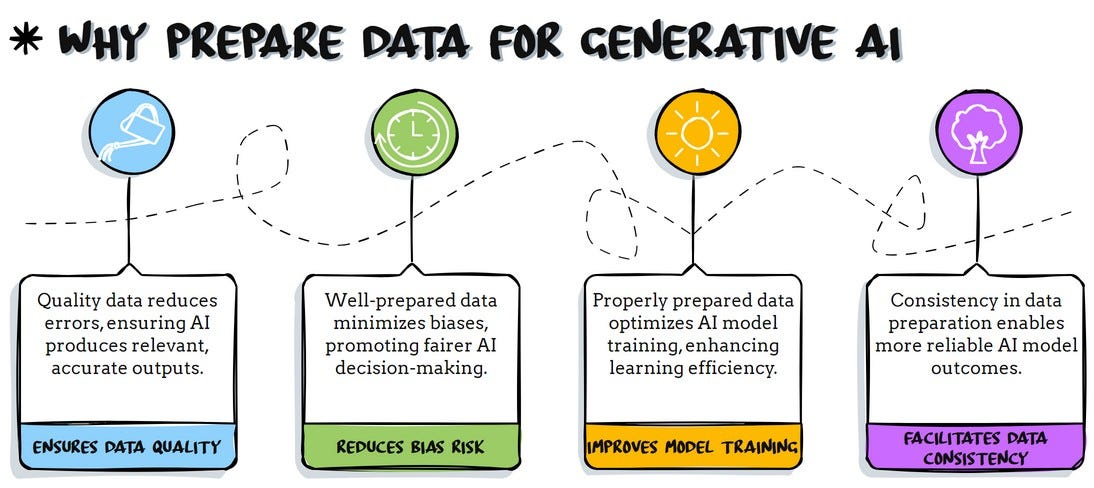
One challenge, though, is that preparing the data for these techniques can be tedious and sometimes inadequate, leading to underwhelming outcomes.
That’s why we’ll explore how to use a Python library to effortlessly prepare your documents for the Gen AI ecosystem.
Curious about it? Let’s get into it!