
Fix it or throw it away: deciding what to do with an AI output
The harder part is knowing which problems you can fix and which ones mean starting over.


An AI tool writes a summary of last quarter’s sales. Most numbers match the source data, but one sentence says a marketing campaign “drove” the revenue lift, and nothing supports that. Fixing it takes thirty seconds: soften the wording or cut the sentence.
Now picture the same summary, just as fluent, except it used the wrong table the whole time. It used gross revenue when the question was about net. Every figure agrees with the others, and every figure is wrong.
Both drafts look the same on screen. One needs a light edit. The other needs to be deleted. Telling those two cases apart, fast, is the skill. The decision is always one of three: use, revise, or reject. What matters is the test underneath it, because that test is where most reviewers go wrong.
The three options
Every output you review ends in one of three actions.
Use. It’s good enough for its next step, even if some polish is left.
Revise. The foundation is sound, but there are fixable flaws worth correcting.
Reject. The foundation itself is broken, so fixing it means rebuilding from scratch.

It’s three actions, not a score. A score tells you how good something looks, not what to do with it. A draft can look like a nine and still belong in the trash, because the one wrong part is what everything else rests on.
So the question is never “how good is this?” It’s: can the problem be fixed, or does it sink the whole thing?
Small flaws and broken foundations
Here is the rule the rest of this article depends on.
Revise when the foundation is sound but the work is incomplete. Reject when the foundation itself is wrong.
A small flaw is one you can fix without touching the core logic, data, or reasoning. Typos, a missing citation when you know the source, a wrong chart label, a caveat that doesn’t change the conclusion, awkward variable names. None of these threaten what’s underneath. You fix them and move on.
A broken foundation invalidates the whole output. The wrong dataset or metric. A source that doesn’t say what’s claimed, or doesn’t exist. Reasoning you can’t trace. Code that runs the wrong algorithm or hardcodes a credential. An answer to a different question than the one asked. You can’t patch these. Every line below the flaw inherits it.

The trap: how bad a flaw is has little to do with how big the fix looks. A broken foundation can be a one-character change, like swapping gross for net. A small flaw can mean rewriting three paragraphs. People reach for reject when the fix looks expensive and use when it looks cheap. That’s backwards. The question isn’t how much text changes. It’s whether the wrong part holds up everything else.
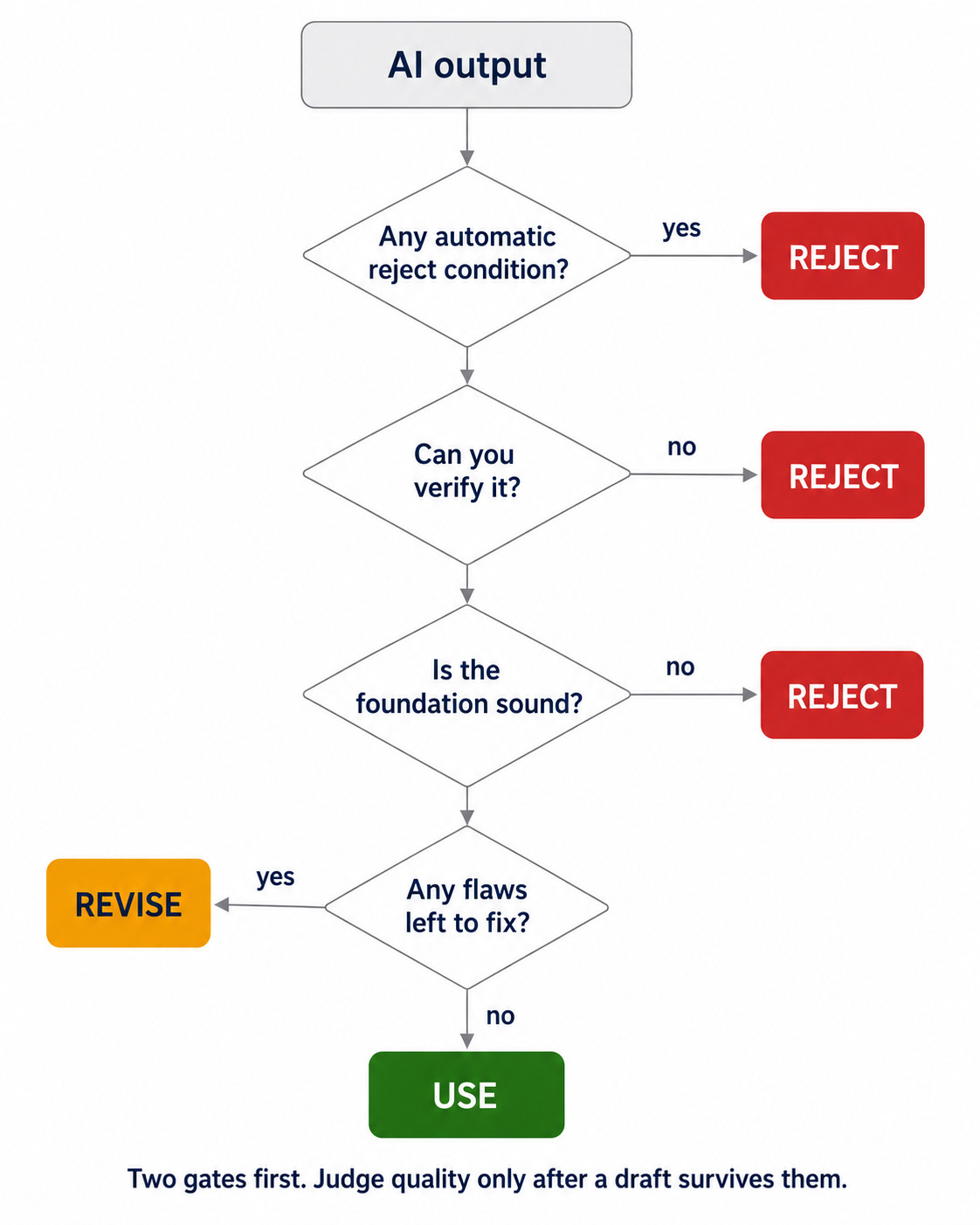
Two checks before you score anything
You can triage most outputs in under a minute with two questions, before any detailed review.
First, is there an automatic reject condition? Invented citations, confidential or out-of-scope data, a policy violation, a badly wrong headline number. If yes, stop and reject. No point scoring the writing on a draft that already failed.
Second, can you verify it? Can you re-run the code, recompute the figure, open every cited source, trace the retrieved context? If you can’t check a claim that matters, don’t approve it because it reads well. These models produce text that sounds right, which is not the same as being right.
Only drafts that pass both checks are worth a full use-versus-revise read.
The same logic in code:
The same logic in code:
if has_critical_violation(output):
decision = "Reject"
elif not is_verifiable(output):
decision = "Reject"
else:
decision = assess(output) # now decide Use vs Revise
What “good enough” means
Use doesn’t mean perfect. It means good enough for the next step, and that bar moves with where the output is going. The same draft can be a use as a private note and a revise as a summary you send to a client. Code that’s fine in a scratch notebook needs real review before production. The bar is highest when an output triggers an action on its own, like sending a notification, because no one stands between it and the result.
So name the next step before you decide. An output is a use only when no remaining problem is big enough to block that step.
Triage by type of output
The line between a small flaw and a broken foundation looks different by output type. Concrete triggers help.
Data analysis. Use it when the dataset and definitions are right, the numbers reconcile, and the logic matches the question. Revise when a causal claim overreaches or a caveat is missing, since that’s fixable with a note while the core data and formulas stay sound. Reject when the metric, grain, or population is wrong, or the question was misread, because every conclusion is then suspect. Wrong data, population, or metric is always a reject.
Code generation. Use it when it runs, passes tests, follows your conventions, and solves the right problem. Revise when it works but needs error handling, better names, or more test coverage. Reject when it uses the wrong algorithm, violates security, hardcodes secrets, or won’t run. “Looks correct” isn’t enough; run it before you trust it.
Retrieved answers. Use it when every factual claim maps to a retrieved passage and the system says “I don’t know” when evidence is thin. Revise when the right documents were pulled but the wording is off or one relevant passage was missed. Reject when it invents facts, cites wrong or fabricated sources, or answers off-context. Keep retrieval and generation separate: if the context is wrong, reject the answer and fix the retrieval.
Dashboards and BI. Use it when the numbers match approved sources, periods and KPIs are consistent, and the interpretation is careful. Revise when the figures are right but the narrative misses a comparison or footnote. Reject when a headline number can’t be traced or filters mix fiscal periods. One wrong headline number spoils the report.
The pattern holds across all four. Style and polish are revise work. Broken substance is reject work. When the wrong part is in the foundation, the data, the retrieval, the algorithm, or the question itself, the answer is reject, no matter how clean the surface looks.
The mistake to watch: editing what you should reject
The expensive mistake isn’t rejecting too much. It’s revising what you should have rejected.
Each round of edits makes a flawed output look better. The writing tightens, the code reads cleaner, and all of it polishes a wrong foundation into something more convincing and harder to catch. A run of reasonable fixes can keep a big error in place and make it look authoritative.
If 90% of a report is good but the core assumption is wrong, reject it. If 10% of otherwise-sound code is missing, revise it. The share that changes is a distraction. What matters is whether you’re polishing something true or dressing up something false.
A simple check: by the third edit on the same output, stop and ask whether you’re fixing flaws or hiding one.
Conclusion
The framework is small on purpose: three outcomes and one test underneath them. When an AI output lands on your desk, don’t grade it. Ask whether the thing that’s wrong sits in the foundation or on the surface.
Surface flaws are revise work. A broken foundation is a reject, however polished it looks, and no amount of editing will fix it. Run the two gates first, name the next step before you decide, and keep a short trail so the same problem doesn’t come back.
Stop asking “how good is this output?” Ask “can the problem be fixed, or does it sink the whole thing?” Use, revise, and reject are the three answers, and getting the question right is most of the skill.