
Machine Learning Explainability Introduction via eli5
Extract insight from your Machine Learning model

Extract insight from your Machine Learning model

Introduction
From my experience working as a Data Scientist, most of the time, you would need to explain why your model is working and what kind of insight your model gives. By insight, I am not referring to the model accuracy or any metric but the machine learning model itself. This is what we called Machine Learning Explainability.
The most straightforward example of Machine Learning Explainability is the Linear Regression Model with the Ordinary Least Square estimation method. Let me give you an example by using a dataset. Note that I violate some of the Ordinary Least Square assumptions, but my point is not about creating the best model; I just want to have a model that could give an insight.
#Importing the necessary packageimport pandas as pdimport seaborn as snsimport statsmodels.api as smfrom statsmodels.api import OLS#Load the dataset and preparing the datampg = sns.load_dataset('mpg')mpg.drop(['origin', 'name'], axis =1, inplace = True)mpg.dropna(inplace = True)#Ordinary Least Square Linear Regression model Trainingsm_lm = OLS(mpg['mpg'], sm.add_constant(mpg.drop('mpg', axis = 1)))result = sm_lm.fit()result.summary()
I would not explain the model in detail, but the Linear model assumed there is linearity between the Independent variables (Features to predict) and the Dependent variable (what you want to predict). The equation is stated below.

What is important here is that every independent variable(x) is multiplied by the coefficient(m). It means that the coefficient tells the relationship between the independent variable with the dependent variable. From the result above, we can see that the coefficient (coef) of the ‘model_year’ variable is 0.7534. It means that every increase of ‘model_year’ by one, the Dependent variable ‘mpg’ value would increase by 0.7534.
The Linear Regression Model with their coefficient is an example of Machine Learning explainability. The model itself is used to explain what happens with our data, and extraction of insight is possible. However, not all model is viable to do this.
Machine Learning Explainability of Black-Box Model
Tree-based Feature Importance
Machine learning model such as random forests is typically treated as a black-box. Why? A forest consists of a large number of deep trees, where each tree is trained on bagged data using a random selection of features. To gaining a full understanding by examining each tree would close to impossible.
For example, the famous XGBoost Classifier from the xgboost package is nearly a black-box model that utilises a random forest process. This model is considered as a black box model because we did not know what happens in the model learning process. Let’s try it using the same dataset as an example.
#Preparing the model and the datasetfrom xgboost import XGBClassifierfrom sklearn.model_selection import train_test_splitmpg = sns.load_dataset('mpg')mpg.drop('name', axis =1 , inplace = True)#Data splitting for xgboostX_train, X_test, y_train, y_test = train_test_split(mpg.drop('origin', axis = 1), mpg['origin'], test_size = 0.2, random_state = 121)#Model Trainingxgb_clf = XGBClassifier()xgb_clf.fit(X_train, y_train)Just like that, we have the model, but did we get any insight from the data? Or could we know the relationship between the dependent to the independent?.
Well, you could argue that the classifier owns a feature importance method which is a tree-model specific to measure how important the feature. To be precise, it measures the feature contribution to the mean impurity reduction of the model.
tree_feature = pd.Series(xgb_clf.feature_importances_, X_train.columns).sort_values(ascending = True)plt.barh(X_train.columns, tree_feature)plt.xlabel('Mean Impurity Reduction', fontsize = 12)plt.ylabel('Features', fontsize = 12)plt.yticks(fontsize = 12)plt.title('Feature Importances', fontsize = 20)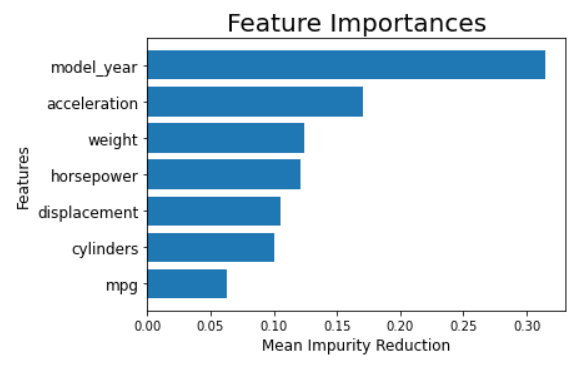
To a certain extent, this is a Machine Learning explainability example. Although, you need to remember that xgboost relies on the bootstrapping process for creating the model. Which means, how important the feature is could happen because of the randomised process. Moreover, the contribution only tells how high the feature could reduce the overall impurity (Overall is the mean from all the produced trees).
Permutation Importance via eli5
There is another way to getting an insight from the tree-based model by permuting (changing the position) values of each feature one by one and checking how it changes the model performance. This is what we called the Permutation Importance method. We could try applying this method to our xgboost classifier using the eli5 package. First, we need to install the package by using the following code.
#installing eli5pip install eli5#orconda install -c conda-forge eli5After installing, we would use the eli5 package from now on for our Machine Learning Explainability. Let’s try the permutation importance for the start.
#Importing the modulefrom eli5 import show_weightsfrom eli5.sklearn import PermutationImportance#Permutation Importanceperm = PermutationImportance(xgb_clf, scoring = 'accuracy' ,random_state=101).fit(X_test, y_test)show_weights(perm, feature_names = list(X_test.columns))
The idea behind permutation importance is how the scoring (accuracy, precision, recall, etc.) shift with the feature existence or no. In the above result, we can see that displacement has the highest score with 0.3797. It means, when we permute the displacement feature, it will change the accuracy of the model as big as 0.3797. The value after the plus-minus sign is the uncertainty value. The permutation Importance method is inherently a random process; that is why we have the uncertainty value.
The higher the position, the more critical the features are affecting the scoring. Some feature in the bottom place is showing a minus value, which is interesting because it means that the feature increasing the scoring when we permute the feature. This happens because by chance the feature permutation actually improves the score.
We have known about both approaches by measuring the impurity reduction and permutation importance. They are useful but crude and static in the sense that they give little insight into understanding individual decisions on actual data. This is why we would use the eli5 weight feature importance calculation based on the tree decision path.
Tree Feature Importance via eli5
Let’s check the XGBoost Classifier feature importance using eli5.
show_weights(xgb_clf, importance_type = 'gain')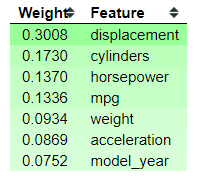
We can see that the ‘displacement’ feature is the most important feature, but we have not yet understood how we get the weight. For that reason, let’s see how the classifier tries to predict for individual data.
#Taking an example of test datafrom eli5 import show_predictionshow_prediction(xgb_clf, X_test.iloc[1], show_feature_values=True)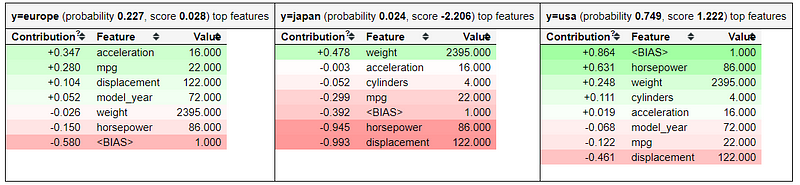
The table above shows us how our classifier predicts our data based on the data given. Every class have their probability and how each feature contributes to the probability and the score (Score calculation is based on the decision path). The classifier also introduce <BIAS> feature which is expected average score output by the model, based on the distribution of the training set. If you want to know more about it, you could check it out here.
What is essential in the above table is that each feature contributed to the prediction result and hence the feature contribution affecting the weight result. Weight is after all the percentage of each feature contributed to the final prediction across all trees (If you sum the weight it would be close to 1).
With this package, we capable to measure how important the feature is not just based on the feature performance scoring but how each feature itself contribute to the decision process.
Conclusion
With eli5, we capable of turning the black-box classifier into a more interpretable model. There are still many methods we could use for the Machine Learning Explainability purposes which you could check in the eli5 homepage.