
Maximizing Machine Learning: How Calibration Can Enhance Performance
The not-so-much talked method to improve our machine learning model

Many machine learning model output is a probability of certain classes. For example, the model classifier would assign a probability to the ‘churn’ class and ‘not churn’ class—say 90% for ‘churn’ and 10% for ‘not churn’.
Generally, the probability would be translated into the prediction. Then we evaluate our model using standard measurements taught in class, such as accuracy, precision, recall, logloss, etc. These measurements were based on discrete outputs such as 0 or 1.
But how do we measure our prediction probability? And how trustworthy is our model probability? To answer these questions, we can use calibration techniques to tell us how much we can trust our prediction probability model.
Calibration Method
Calibration in machine learning is a method that refers to the action of adjusting the probabilistic model output to match the actual output. What is it means to match the actual output?
Let’s say we have a classification model predicting churn with a 70% probability for each prediction; it means it ‘should’ be correct 7 out of 10 times. If we take data for 10 customers and find 7 customers were churned, the model is well-calibrated.
However, in many classification models, the probability output does not calibrate well. Often, a mismatch happens between the output and the actual result—which we call a miscalibrated model.
If we make an example,
A model with 60% probability prediction each time with an actual true result of 70%—The model is underconfidence with its’s prediction and miscalibrated.
A model with 80% probability prediction each time with an actual true result of 70%—The model is overconfident with its’s prediction and miscalibrated.
A model with 70% probability prediction each time with an actual true result of 70%—The model is well-calibrated.
Calibration addresses this issue by adjusting the output of the model to better match the actual probabilities of the events.
Calibration Curve
The standard way to check the model’s calibration is by using Calibration Curve or Calibration plot. The plot shows discrepancies between the model’s probability output and the actual data’s probabilities.
If we have a perfectly calibrated model, the ideal result would be a straight line where the predicted probabilities are always the same as the real ones. What we want is a curve that is as straight as possible.
A calibration curve is created by binning the model’s output probabilities (often 10 bins), and for each bin, the percentage of the true samples is calculated. We can expect the percentage samples in the bin center if the model is perfectly calibrated. e.g., for bin between 90% to 100% is expected to have a 95% true result.
Let’s try to create the Calibration Curve with sample data. We would use the titanic dataset from the Seaborn package and Calibration Curve from Scikit-Learn.
First, we prepared the dataset we would use for training the model.
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
import seaborn as sns
titanic = sns.load_dataset('titanic')
#Data Preprocessing
titanic = titanic.drop(['deck', 'who', 'adult_male', 'alive', 'embark_town'], axis =1)
titanic = titanic.dropna()
titanic['alone'] = titanic['alone'].apply(lambda x: 1 if x == True else 0)
titanic = pd.get_dummies(titanic, columns = ['sex', 'embarked', 'class'])Next, we would split the dataset into train and test data.
from sklearn.model_selection import train_test_split
# Splitting dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(titanic.drop('survived', axis =1), titanic['survived'], test_size = 0.2, random_state = 42)After splitting the data, we would create a probabilistic classifier model. For our example, we would use the Decision Tree Classifier.
from sklearn.tree import DecisionTreeClassifier
# Model Training
model = DecisionTreeClassifier()
model.fit(X_train, y_train)
# Predict Probabilities
prob = model.predict_proba(X_test)With our model trained and the probabilistic output ready, we can create the Calibration Curve.
from sklearn.calibration import calibration_curve
# Calibration Curve with Scikit-Learn
x, y = calibration_curve(y_test, prob[:, 1], n_bins = 10, normalize = True)
# Plot perfectly calibrated
plt.plot([0, 1], [0, 1], linestyle = '--', label = 'Perfect Calibrated')
# Plot model's calibration curve
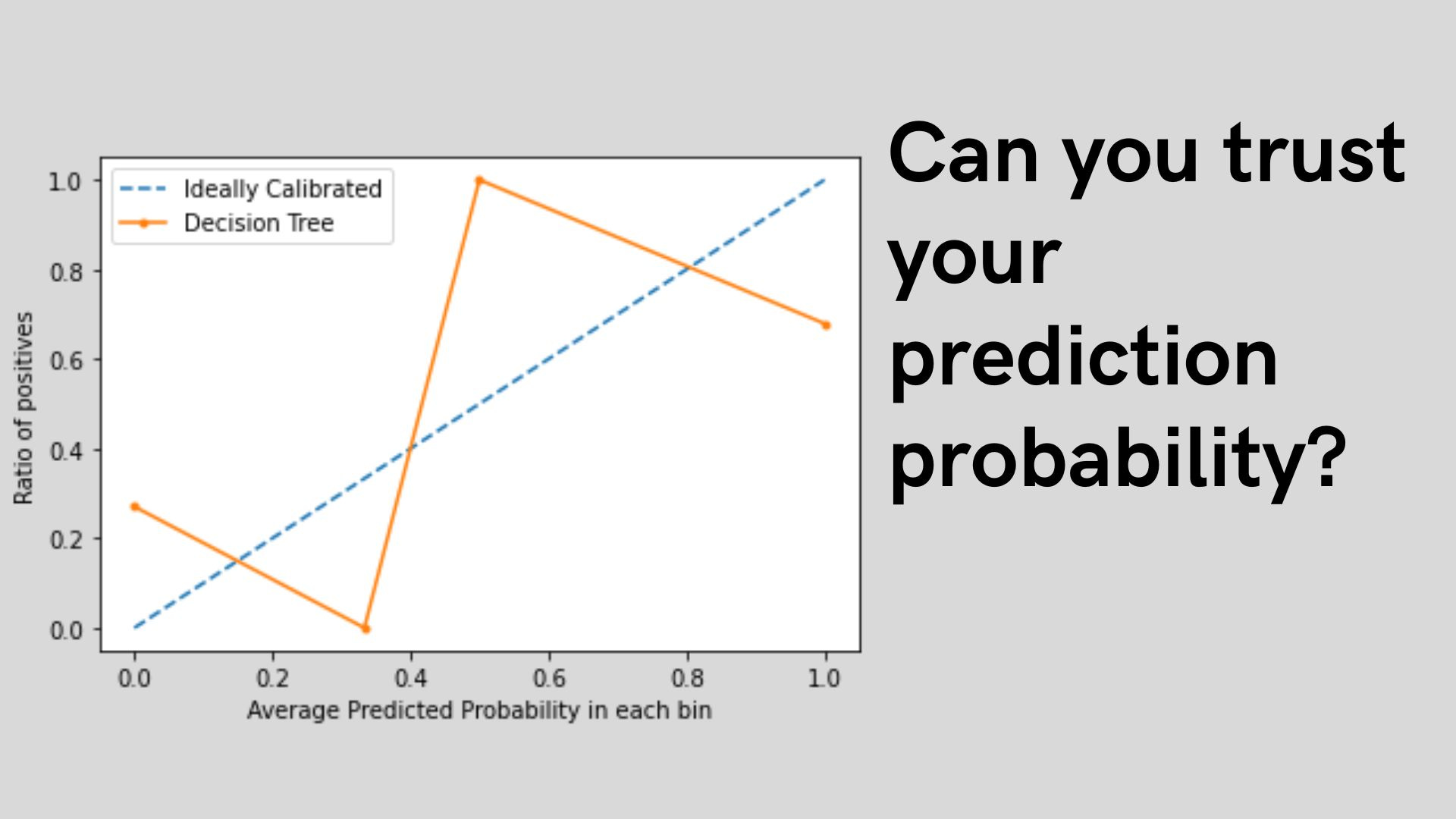
plt.plot(y, x, marker = '.', label = 'Decision Tree')
plt.legend(loc = 'upper left')
plt.xlabel('Average Predicted Probability in each bin')
plt.ylabel('Ratio of positives')
plt.show()
The result shows a not-calibrated curve, as the model calibration curve is not linear and is either underconfidence or overconfident for many of the predictions.
Additionally, we can use a measurement called Brier Score Loss to measure the mean squared error between the actual data compared to the probability output for the binary classifier. The score range is between 0 to 1, where 0 means perfect calibration. We want to aim for the lowest score as much as possible.
from sklearn.metrics import brier_score_loss
brier_score_loss(y_test, prob[:, 1]
As the image above shown, the score could still be better. Now, let’s learn how to improve our model calibration.
Model Calibration
The most common method to calibrate the model is by using the method we call the sigmoid method and isotonic regression. Both methods would try to make the prediction probability close to the ideal. Let’s use the provided classifier using Scikit-Learn.
from sklearn.calibration import CalibratedClassifierCV
calibrated_model = CalibratedClassifierCV(model, cv = 3, method = 'sigmoid')The model we fitted would now act as the classifier but is still based on the probabilistic model we used initially.
calibrated_model.fit(X_train, y_train)
prob_cal = calibrated_model.predict_proba(X_test)Let’s see the calibrated model’s new calibration curve.
x, y = calibration_curve(y_test, prob_cal[:, 1], n_bins = 10, normalize = True)
plt.plot([0, 1], [0, 1], linestyle = '--', label = 'Perfect Calibrated')
plt.plot(y, x, marker = '.', label = 'Decision Tree Calibrated')
leg = plt.legend(loc = 'upper left')
plt.xlabel('Average Predicted Probability in each bin')
plt.ylabel('Ratio of positives')
plt.show()
We can now see the curve is closer to the straight line. Let’s see the Brier Score to see the actual changes.
brier_score_loss(y_test, prob_cal[:, 1])
The number is undoubtedly decreasing compared to before. While it’s not a perfectly calibrated model, we still managed to have a better-calibrated model that would improve the model’s performance.
Conclusion
Many probabilistic models are not calibrated and might have misleading results. To have a better result, we can check and perform the calibration. The result would improve the model performance.