
Metode Feature Importance dalam Data Science yang Perlu Kamu Ketahui
Sebagai seorang Data Scientist, saya sering mendengar bahwa Machine Learning adalah alasan seseorang memasuki bidang Data Science. Walau…


Sebagai seorang Data Scientist, saya sering mendengar bahwa Machine Learning adalah alasan seseorang memasuki bidang Data Science. Walau begitu, kebanyakan individu hanya mampu membuat dan menggunakan model Machine Learning ini tanpa paham bagaimana mereka bekerja; atau bahkan menjelaskan hal yang mampu didapatkan melalui model Machine Learning. Padahal, kemampuan untuk memahami model Machine Learning adalah hal yang harus dimiliki untuk menjadi seorang Data Scientist yang sesungguhnya. Oleh karena itu, saya ingin menjelaskan beberapa teknik yang bisa digunakan untuk mendapatkan Insight dari suatu model Machine Learning.
Feature Importance
Membangun suatu model prediksi tidaklah susah, kita hanya perlu beberapa baris kode untuk mendapatkan model prediksi terebut. Model kita bahkan bisa kita atur sedemikian rupa untuk dapat memiliki performa yang bagus di data test.
Terus, kenapa kita perlu memahami model kita jika sudah memiliki hasil yang bagus? Nah, bayangkan jika kalian adalah stakeholder yang menginvestasikan dana kalian untuk membuat suatu model prediksi. Setelah beberapa lama membuat model, kalian ditunjukkan suatu model prediksi yang memiliki Performance metrics sangat bagus. Apakah kalian sebagai stakeholder akan menerima begitu saja model tersebut untuk bisnis kalian? mungkin saja, tetapi saya yakin jawaban seharusnya adalah tidak. Stakeholder pastinya punya hak untuk mendapatkan insight kenapa model ini bisa bekerja dengan baik. Karena itu, memahami apa yang terjadi di dalam model kita sangat penting.
Selain spesifikasi model, Feature yang dimiliki oleh data akan menjadi pusat utama untuk menjelaskan model prediksi yang kita latih. Feature Importances sehingga bisa dikatakan sebagai tolak ukur besaran kontribusi berbagai data feature yang dilatih kepada performa model prediksi.
Model Training
Saya akan berikan sedikit contoh melalui kode Python. Semisal, kita ingin memprediksi apakah seseorang memiliki penyakit jantung atau tidak. Data yang saya gunakan adalah Heart Disease Dataset dari data untuk kompetisi di Data Driven. Untuk masalah binary classification seperti ini, banyak pilihan model yang bisa digunakan tetapi saya hanya akan menggunakan 1 model Random Forest dengan parameter default saja sebagai model contoh kita. Selain itu, saya tidak akan melakukan Evaluasi yang mendalam karena fokus kita di artikel kali ini adalah memahami apa yang dimaksud Feature Importance dan bagaimana mendapatkan insight dari model Machine Learning.
import pandas as pdimport matplotlib.pyplot as plt from sklearn.ensemble import RandomForestClassifierfrom sklearn.metrics import classification_report, roc_curve, aucfrom sklearn.model_selection import train_test_splitX = pd.read_csv('train_values.csv', index_col = 'patient_id')y = pd.read_csv('train_labels.csv', index_col = 'patient_id')X = pd.get_dummies(data = X, columns = ['thal'], drop_first = True)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 101)Saya hanya sedikit melakukan preprocessing dengan cara one-hot encoding kepada kolom ‘thal’, untuk kolom yang lain saya biarkan seperti yang ada. Setelah itu saya membagi data yang ada menjadi 8:2 untuk Train:Test. Sekarang kita akan mencoba membuat model prediksi kita.
classifier = RandomForestClassifier()classifier.fit(X_train,y_train)Lihat, betapa mudahnya untuk melatih suatu model prediksi. Dengan 2 baris kode saja kita sudah mendapatkan suatu model prediksi. Sekarang kita akan mengevaluasi model kita lebih jauh.
PredictProb = classifier.predict_proba(X_test)preds = PredictProb[:,1]fpr, tpr, threshold = roc_curve(y_test, preds)roc_auc = auc(fpr, tpr)plt.figure(figsize=(10,8))plt.title('Receiver Operator Characteristic')plt.plot(fpr, tpr, 'b', label = 'AUC = {}'.format(round(roc_auc, 2)))plt.legend(loc = 'lower right')plt.plot([0,1], [0,1], 'r--')plt.xlim([0,1])plt.ylim([0,1])plt.ylabel('True Positive Rate')plt.xlabel('False Positive Rate')plt.show()
Dari model yang baru saja kita buat, model kita sepertinya memiliki kemampuan prediksi yang baik terhadap data test(AUC sebesar 86%, Akurasi 72%) walau tentunya masih bisa jauh ditingkatkan.
Sekarang kita akan mencoba menganalisis bagaimana feature data berpengaruh kepada performa model.
Tree-Specific Feature Importance
Algoritm dari Random Forest yang dimiliki oleh Scikit-learn menyediakan perhitungan untuk mengukur feature importances. Hal ini dilakukan dengan cara menghitung rata-rata pengurangan reduksi impurity yang dihasilkan oleh suatu fitur di seluruh pohon.
tree_feature = pd.Series(classifier.feature_importances_, X.columns).sort_values(ascending = True)plt.figure(figsize = (8,8))plt.barh(X.columns, tree_feature)plt.xlabel('Mean Impurity Reduction', fontsize = 12)plt.ylabel('Features', fontsize = 12)plt.yticks(fontsize = 12)plt.title('Feature Importances', fontsize = 20)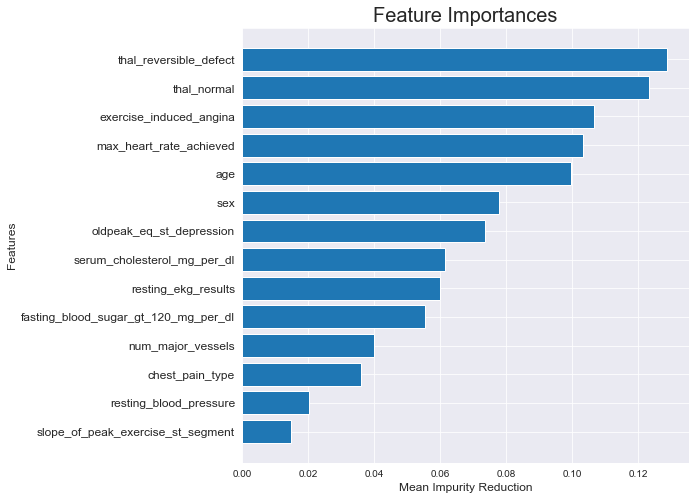
Dari plot diatas, kita dapat melihat bahwa fitur thal yang paling membantu model kita untuk membedakan pasien dengan penyakit jantung atau tidak adalah fitur thal. Jika kita jabarkan, Node split di fitur thal secara umum akan sangat mengurangi Impurity dari suatu Node. Kedua fitur thal kita berada di urutan paling atas, hal ini tidak mengherankan karena kedua fitur tersebut memang berkorelasi. Thal sendiri adalah Thalium Stress Test yang mengukur bagaimana darah kita mengalir ke jantung, sehingga tidak heran jika fitur ini sangat berpengaruh terhadap model prediksi.
Permutation Importance
Permutation Importance adalah algoritm untuk mendapatkan informasi Feature Importance dengan melakukan permutasi (menyusun ulang kumpulan data) di fitur yang digunakan dalam melatih model prediksi. Proses yang dilakukan simpel; melatih model prediksi -> permutasi fitur di data-> evaluasi kembali model.
Jika suatu fitur tidak terlalu berkontribusi kepada performa suatu model, maka dengan merubah susunan data tidak akan ada pengaruh yang berarti; sebaliknya, suatu fitur yang berkontribusi besar akan sangat berpengaruh kepada performa model jika dirubah susunan datanya.
from eli5 import show_weightsfrom eli5.sklearn import PermutationImportanceperm = PermutationImportance(classifier, scoring = 'roc_auc' ,random_state=101).fit(X_test, y_test)show_weights(perm, feature_names = list(X_test.columns))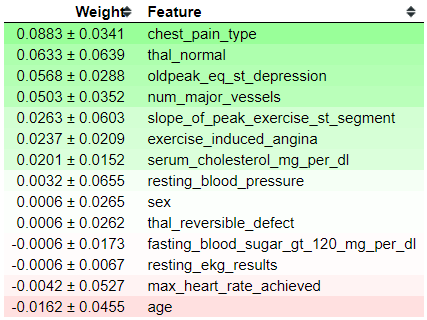
Tabel diatas menunjukkan bagaimana pengaruh Permutasi terhadap performa model. Nah, bagaimana cara kita membaca tabel ini? Fitur-fitur yang berada diatas adalah fitur yang paling berpengaruh, dan semakin kebawah pengaruhnya semakin tidak ada. Angka yang pertama di setiap row (sebelum tanda ±) adalah seberapa besar performa metriks (kali ini saya menggunakan ROC-AUC) kita yang berubah dengan melakukan permutasi data. Angka setelah tanda ± adalah seberapa besar variasi performa model kita. Kita juga melihat ada angka dengan tanda negatif (-), hal ini menandakan bahwa fitur yang sebenarnya tidak berkaitan terkadang dapat meningkat performa model karena suatu keberuntungan dari acakan data.
Pengunaan Permutation Importance itu sangat berguna karena kita dapat mengatur performa metriks yang ingin kita ukur (Tree-Specific hanya mengukur dari Node impurity saja). Selain itu kita dapat mengukur tingkat variasi yang dimiliki setiap fitur; fitur-fitur yang berada diatas bukan berarti yang paling berkontribusi kepada performa model, terkadang ada fitur yang memiliki variasi besar dimana menghilangkan fitur tersebut akan sangat mempengaruhi performa model.
Kalau kita melihat dari tabel diatas, chest_pain_type yang paling berpengaruh terhadap model prediksi kita. Tidak mengherankan juga jika fitur ini sangat berpengaruh, karena semakin terasa sakit dada kita maka kemungkinan adanya penyakit jantung juga semakin besar. Selain itu, fitur thal juga masih berpengaruh terhadap performa model kita.
SHapley Additive exPlanations (SHAP)
SHAP adalah algoritm favorit saya untuk mendapatkan insight dari Machine Learning model kita. Jika algoritm diatas berbicara secara utuh bagaimana setiap fitur mempengaruhi performa model, SHAP lebih spesifik memperhitungkan bagaimana setiap spesifik fitur berpengaruh kepada setiap prediksi yang dilakukan.
Kita akan langsung mencoba saja melakukan prediksi dan visualisasi SHAP kita.
import shap#Kita menggunakan explainer untuk menjelaskan output dari model. SHAP memiliki explainer khusus untuk model spesifik ataupun yang umum untuk semua modelexplainer = shap.TreeExplainer(classifier)#Perhitungan SHAP value, yaitu perhitungan bagaimana setiap fitur berkontribusi kepada prediksi yang dilakukan. Saya secara acak menggambil data di row ke 1shap_val = explainer.shap_values(X_test.iloc[1])#Memvisualisasikan pengaruh setiap fitur terhadap prediksi yang dilakukan. Disini dispesifikasikan untuk prediksi class 1 di row ke 1shap.initjs()shap.force_plot(explainer.expected_value[1], shap_val[1], X_test.iloc[1])
Bagaimana kita mengintrepetasikan gambar diatas, beserta nilai-nilai yang muncul?
Kita lihat dahulu dari kode diatas; untuk explainer.shap_values, kode ini akan menghitung nilai SHAP setiap fitur terhadap prediksi yang dilakukan. Nilai yang dihasilkan akan berupa seluruh perhitungan SHAP untuk setiap kelas. Explainer sendiri akan menghasilkan nilai base value, dimana secara umum adalah rata-rata output model berdasarkan training yang dimasukkan. SHAP values ini nantinya yang akan memperhitungan seberapa jauh setiap fitur berkontribusi untuk mengurangi atau menambahkan base value kita ke output yang terlihat.
Kembali ke gambar kita diatas. Gambar diatas menunjukkan bahwa untuk kelas 1, kita mendapatkan probability output 0.6. Hal ini dilakukan karena dimulai dari base value kita 0.3951, nilai ini terdorong ke arah kanan menuju 0.6 berdasarkan fitur-fitur yang berwarna merah. Fitur oldpeak_eq_st_depression = 3.1 sepertinya yang paling berkontribusi besar, disusul thal_reversible_defect = 1. Sebaliknya fitur serum_cholestrol_mg_per_dl = 203 yang berkontribusi untuk mengurangi shap value kita.
shap_val = explainer.shap_values(X_test)shap.summary_plot(shap_val, X_test)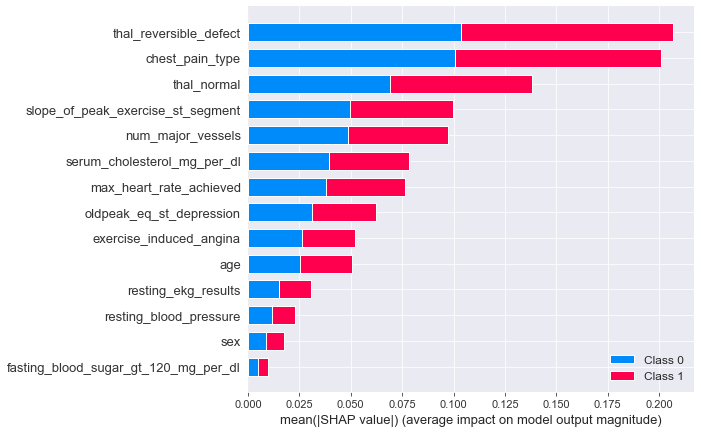
Selain itu kita bisa membuat stacked baraplot untuk rata-rata absolut (Mean Absolute) dari SHAP value untuk setiap fitur. Plot ini bisa memberikan penjelasan, seberapa besar kontribusi suatu fitur kepada prediksi setiap kelas. Dari gambar diatas, bisa terlihat bahwa fitur thal dan chest_pain_type sekali lagi menjadi fitur yang paling berkontribusi untuk membedakan suatu kelas.
Kesimpulan
Kita baru saja mendapatkan suatu insight dari data melalui model Machine Learning. Kali ini data yang kita miliki memang memiliki fitur-fitur yang secara umum mudah untuk membantu kita melakukan prediksi. Tetapi biasanya data di dunia nyata tidak sebersih ini. Oleh karena itu, dengan metode Feature Importances kita bisa mengetahui fitur penting dari suatu data yang sebelumnya tidak kita ketahui.