
MLOps Basic Open-Source Tool Series #5: Evidently AI for Comprehensive Monitoring
The fifth edition that would discuss the Monitoring open-source tool called Evidently AI to check your model in production.

This newsletter is part of a series introducing open-source tools used in Machine Learning Operations (MLOps). Each series will introduce new tools for different parts of the process. We would combine everything at the end of the series to make a cohesive MLOps project.

Hey guys! It’s nice to be back to write the new part of our MLOps Open-Source tool series. I am sorry that I am taking a break for a few weeks. We will come back to learn a new tool now.
In this edition, we will learn the open-source MLOps tool called evidently.ai. It’s a tool specifically developed to test and monitor data and ML models in production.
We know the machine learning model is the center of any machine learning project. Without a working model, there would be no value given to the business.
However, the ML model is not a one-time object you train and leave as it is. You need to re-evaluate your model continuously to see if the output is still valid at that time. This is where we can rely on the monitoring open-source tool.
Evidently, AI is an open-source tool that reliably evaluates and tests the ML model in production. It’s a complete tool that can control our model in many situations.
Curious about it? So, let’s learn Evidently AI further!
If you miss my previous series, you can read it below.
MLOps Basic Open-Source Tool Series #4: Deepchecks Testing for Data and Model Testing Validation

This newsletter is part of a series introducing open-source tools used in Machine Learning Operations (MLOps). Each series will introduce new tools for different parts of the process. We would combine everything at the end of the series to make a cohesive MLOps project.
Machine Learning Monitoring with Evidently AI
As mentioned previously, Evidently AI is an open-source tool for validating and evaluating ML models in production. It can be used for tabular, text, and embedding data.
Evidently AI mainly helps monitor models by analyzing their performance and identifying any issues related to data drift, model drift, and data quality. The tool can provide Evaluation Metrics and Dashboard Reports that give insights into the model's performance and the data's behavior.
The metrics and dashboard usually focus on different aspects, such as:
Data Drift: Measures how much the statistical properties of the model input features have changed over time. This can signal that the model might not perform as expected because the conditions under which it was trained have changed.
Model Performance: Evaluates changes in model performance metrics over time, helping to catch issues like model degradation.
Target Drift: Looks at changes in the distribution of the target variable in supervised learning tasks.
Data Quality: Assesses the quality of incoming data, checking for missing values, unexpected distributions, or outliers that could affect model performance.
With that in mind, we would use Evidently AI to generate reports to monitor our data and model in production.
Let’s start by installing the Evidently AI package with the following code.
pip install evidentlyIf you want the Evidently report in the Jupyter Notebook, we need to install the nbextension and enable. You can do it by running the following code in the command prompt.
jupyter nbextension install --sys-prefix --symlink --overwrite --py evidentlyAnd enable them with the following code.
jupyter nbextension enable evidently --py --sys-prefixOnce everything is installed perfectly, we will try to monitor our data and machine learning model. We would use sample data to check the data drift in this example.
Data Drift Detection
First, let’s load the dataset example.
from sklearn.datasets import fetch_california_housing
data = fetch_california_housing(as_frame=True)
housing_data = data.frameWe would set the data target from this data and tweak it a bit so it could simulate the prediction data.
housing_data.rename(columns={'MedHouseVal': 'target'}, inplace=True)
housing_data['prediction'] = housing_data['target'].values + np.random.normal(0, 5, housing_data.shape[0])From the data, we would simulate the reference (the past data for training) and the current data.
reference = housing_data.sample(n=5000, replace=False)
current = housing_data.sample(n=5000, replace=False)Then, we would initiate the data drift detection report with the following code.
from evidently.report import Report
from evidently.metric_preset import DataDriftPreset
report = Report(metrics=[
DataDriftPreset(),
])
report.run(reference_data=reference, current_data=current)
report
You will see a complete report of the reference and current data drift report. As you can see in the report above, there is much information for each column about whether there is a drift. This also includes the prediction column, an important part of the model.

Data Tests
Evidently AI also provides tests that can be performed on the data. The test can be anything, from detecting missing values and duplicate rows to data drift. Let’s take an example with this code.
from evidently.test_suite import TestSuite
from evidently.tests import *
tests = TestSuite(tests=[
TestNumberOfColumnsWithMissingValues(),
TestNumberOfRowsWithMissingValues(),
TestNumberOfConstantColumns(),
TestNumberOfDuplicatedRows(),
TestNumberOfDuplicatedColumns(),
TestColumnsType(),
TestNumberOfDriftedColumns(),
])
tests.run(reference_data=reference, current_data=current)
tests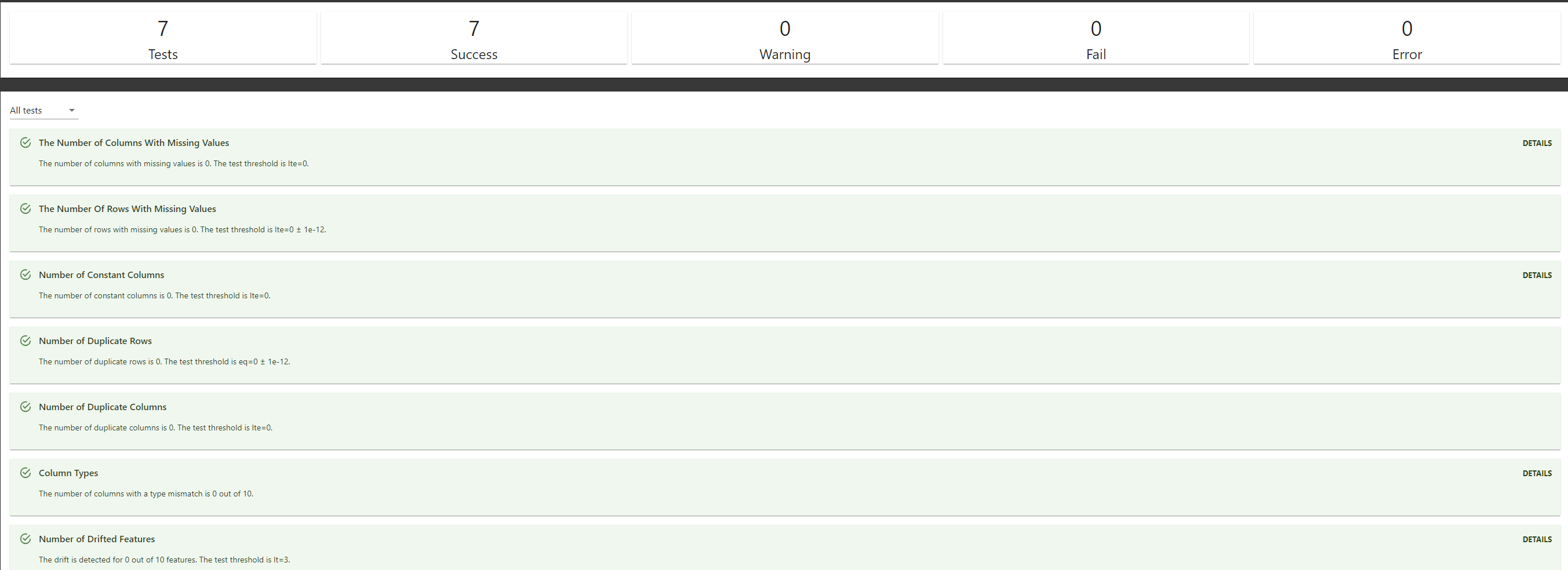
You can get the report to see if the data have passed the test. This would be important to maintain the data quality that came to the production and ensure a smooth process.
That’s all for today's open-source tool. We will try to explore Evidently AI later in more depth when we combine all the tools together, as we want to use the individual test rather than the whole report.
Conclusion
This is the fifth part of the MLOps basic series. We have already learned a simple introduction to comprehension monitoring with Evidently AI.
We will continue to learn the MLOps basics in the following newsletter and combine everything. So, stay tuned!