
MLOps Basic Open-Source Tool Series #4: Deepchecks Testing for Data and Model Testing Validation
The fourth in series of MLOps open-source tools. This edition would discuss the importance of validate the data and model before moving into production.

This newsletter is part of a series introducing open-source tools used in Machine Learning Operations (MLOps). Each series will introduce new tools for different parts of the process. We would combine everything at the end of the series to make a cohesive MLOps project.

Let’s continue our discussion regarding MLOps open-source tools. This time, we will talk about the data and model validation tool.
Machine learning projects hearts is the data, and the model is only as good as the process to generalize the data. We must maintain the data and model components to provide the necessary business values.
Nevertheless, validating the components in a complex machine learning project is challenging. Manual testing could provide the best result, but it’s time-consuming and inflexible to do them every time. Therefore, we can rely on automation tools to validate our dataset and model.
One of the open-source tools to validate our data and model is Deepchecks. It’s a holistic tool that provides tests to the ML project. From the development phase to the production, the package provides an easy way to validate our project.
So, how does Deepchecks work, and what values would these tools bring? Let’s try it out.
If you miss my previous series, you can read it below.
MLOps Basic Open-Source Tool Series #3: DVC for Data Versioning

This newsletter is part of a series introducing open-source tools used in Machine Learning Operations (MLOps). Each series will introduce new tools for different parts of the process. We would combine everything at the end of the series to make a cohesive MLOps project.
Data and Model Validation with Deepchecks
Deepchecks boast themselves as Continuous Validation tools that support all the machine learning project validation needs.
The tools provide them all, from the requirements testing to the model evaluation. The Deepcheks validation approach is based on testing the ML models and data in the machine learning lifecycle with simple APIs and easy-to-digest results.
The tools also give several options, depending on the use cases: tabular, NLP, and vision. In our example, we would only check out the tabular data model.
Let’s start with installing the Deepchecks package.
pip install deepchecksNext, we would try the tabular data and model validation from Deepcheks. For this example, I would use the vehicle fraud claim dataset from Kaggle. It’s tabular data for classification use cases often encountered in real-world situations.
import pandas as pd
df = pd.read_csv('fraud_oracle.csv')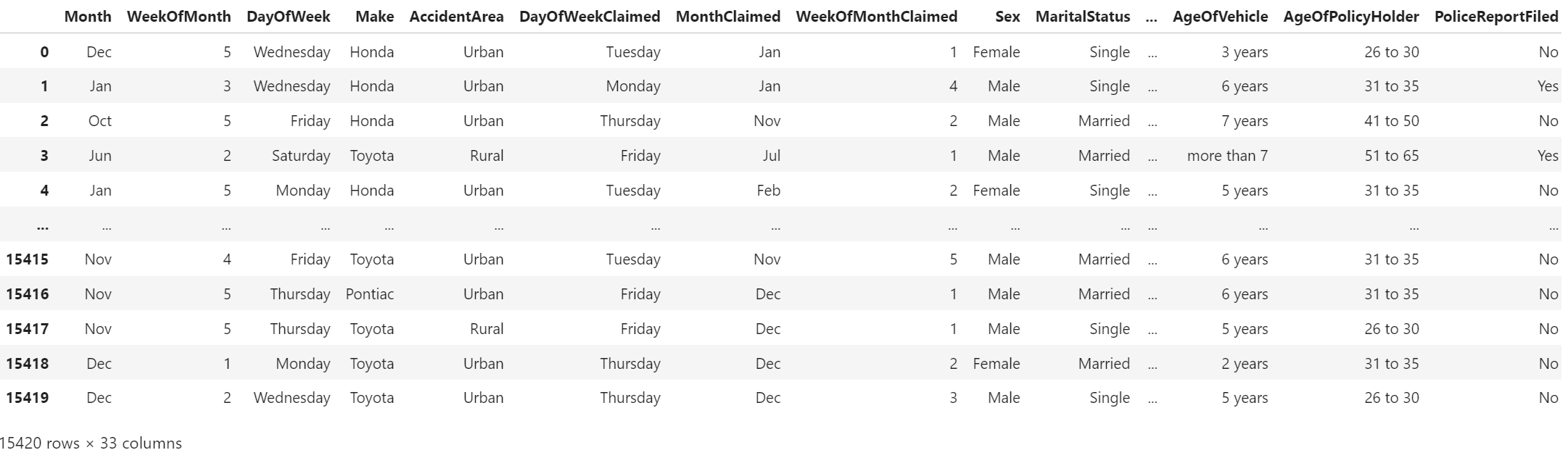
There are 15420 rows with 33 columns, with the column FraudFound_P as the label. We would assume this dataset as our ground truth and the first time we handling them.
Data Integrity Validation
In the data science lifecycle, we want to perform EDA on our dataset so we can understand them. To ensure that the dataset integrity is appropriate and we have quality data, we can use Deepchecks to validate them.
To perform the data integrity validation, we need to set the dataset for the Deepchecks initially.
from deepchecks.tabular import Dataset
cat_feats = df.select_dtypes('object').columns.to_list()
ds = Dataset(df, cat_features=cat_feats , label= 'FraudFound_P', index_name = 'PolicyNumber')If you have one, the dataset object also accepts the datetime column name. The object also automatically infers from our DataFrame, but it’s better if we set the metadata by ourselves.
Next, we run the data integrity validation with the following code.
from deepchecks.tabular.suites import data_integrity
integ_suite = data_integrity()
suite_result = integ_suite.run(ds)
suite_result.show()You will get a result similar to the image below.

Inside them, you can find whether or not your dataset has passed the specific validation tests. For example, it’s what it looks like for the test we didn’t pass.

If you are curious about all the tests performed by Deepchecks and want to run a single test, you can check out their Data Integrity API documentation.
Lastly, using the following code, you can transform the result into JSON data for subsequent processes.
suite_result.to_json()
Train Test Validation
After the EDA process, the model training process requires us to split the data. Luckily, Deepchecks also gives API to validate the splitting data process.
Let’s try it out by splitting our dataset first.
from sklearn.model_selection import train_test_split
train, test = train_test_split(df, random_state = 42, test_size = 0.2)Then, we initiate the dataset similar to the previous section, but this time, we make them for the train and test data.
from deepchecks.tabular import Dataset
train_ds = Dataset(train,cat_features=cat_feats, index_name='PolicyNumber', label= 'FraudFound_P')
test_ds = Dataset(test,cat_features=cat_feats, index_name='PolicyNumber', label= 'FraudFound_P')Lastly, we perform the train test validation with the following code.
from deepchecks.tabular.suites import train_test_validation
validation_suite = train_test_validation()
suite_result = validation_suite.run(train_ds, test_ds)
suite_result.show()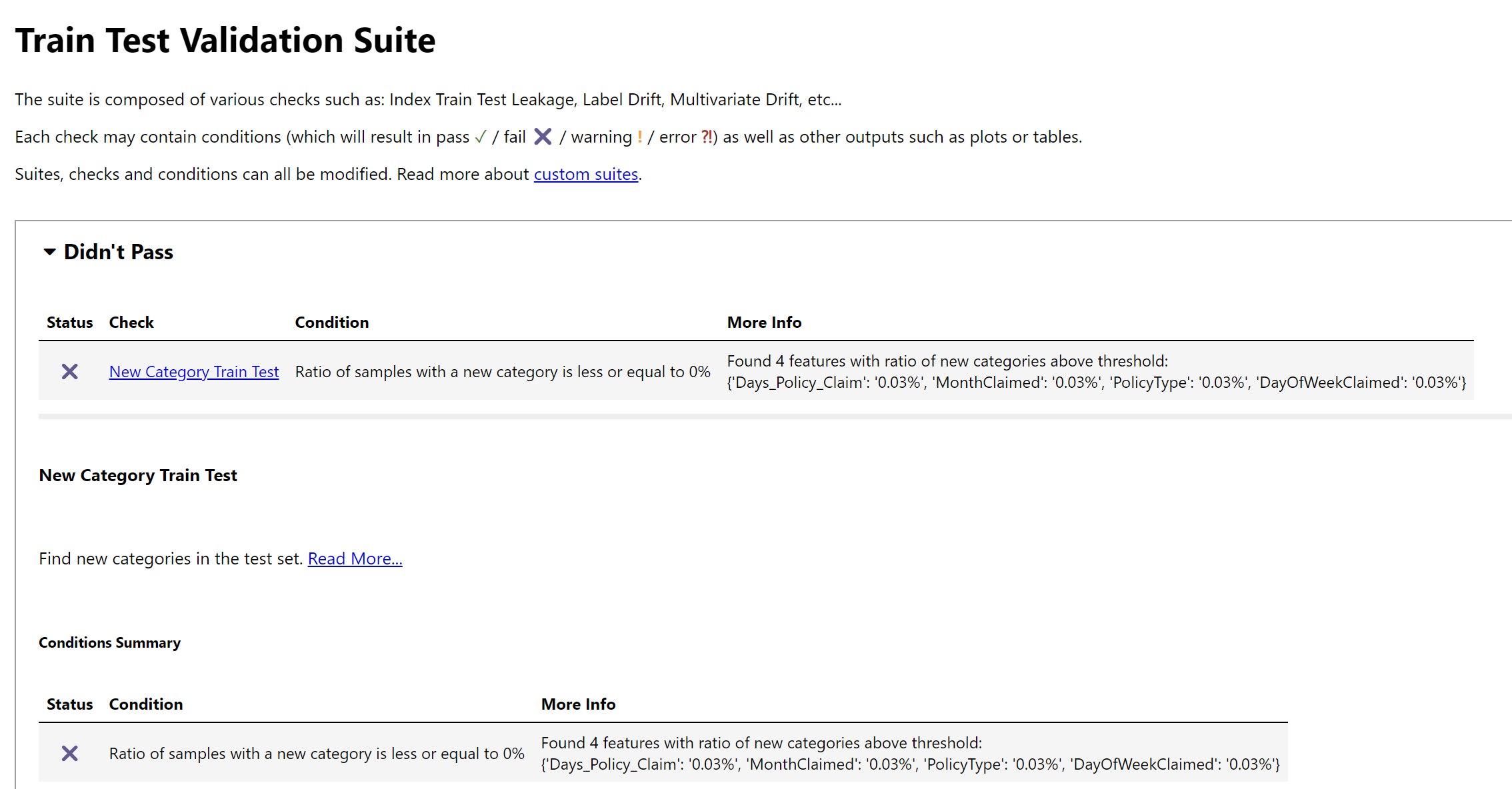
The result would be similar to the Data Integrity tests, where we see which test passed and which did not. You can check the train test validation documentation to see which test is performed.
Model Validation
We can train our model with our training dataset being split and ready to use. In this phase, Deepchecks also provides a way to validate our model.
Let’s try them out. For this example, I would only take some features for the modeling process.
df_to_model = df[['WeekOfMonth', 'Age', 'RepNumber', 'Deductible', 'DriverRating', 'FraudFound_P']]Then, we would split the data once more. This time, we would differentiate the label and the features.
X_train, X_test, y_train, y_test = train_test_split(df_to_model.drop('FraudFound_P', axis =1), df_to_model['FraudFound_P'], test_size = 0.2, random_state = 42)For the model, we would use the Random Forest Classifier from Sklearn.
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier(random_state=0)
rf_clf.fit(X_train, y_train)When the model is ready, we will validate it using Deepchecks. First, let’s initiate the Dataset object. This time, we would not assign any categorical features inside the parameters as there are no categorical features.
from deepchecks.tabular import Dataset
train_ds = Dataset(X_train, label=y_train, cat_features=[])
test_ds = Dataset(X_test, label=y_test, cat_features=[])Then, we would initiate the model evaluation with Deepchecks.
from deepchecks.tabular.suites import model_evaluation
evaluation_suite = model_evaluation()
suite_result = evaluation_suite.run(train_ds, test_ds, rf_clf)
suite_result.show()
You can check the complete model validation documentation for all the tests performed by Deepchecks.
Full Validation
Lastly, Deepchecks also provides the ability to run the whole test, from data integrity to model validation. The process is called complete suites.
To do that, we can run them with the following code.
from deepchecks.tabular.suites import full_suite
suite = full_suite()
suite_result = suite.run(train_dataset=train_ds, test_dataset=test_ds, model=rf_clf)
suite_result.show()
The tests above can be done even with the new data after the model is in production. The data integrity tests are used for the new dataset before the training process, and the train test split validation is used to compare the old and new data.
Using the result from Deepchecks, you can decide if the dataset or model suits the production. We will try to utilize the results from Deepchecks in more depth later on for the whole MLOps process.
Conclusion
This is the fourth part of the MLOps basic series. We have already learned a simple introduction to data and model validation with Deepchecks.
We will continue to learn the MLOps basics in the following newsletter and combine everything. So, stay tuned!