
MLOps Basic Open-Source Tool Series #2: MLFlow for Model Registry
Managing model is important in the production environment. The second edition would discuss more in-depth about Model Registry.

This newsletter is part of a series introducing open-source tools used in Machine Learning Operations (MLOps). Each series will introduce new tools for different parts of the process. We would combine everything at the end of the series to make a cohesive MLOps project.

Machine Learning Model development is an activity to experiment and retrain the model until we acquire the best model. However, the machine learning model would always need retraining as real-world conditions often change.
In the production environment, we need to keep track of every deployed model and use it to track the values and maintain integrity. That’s why it’s important to keep a stable model registry.
In the first series, we learned how to use MLFlow for experiment tracking and model management. I realized that the first series focused more on the experiment part rather than the model management, so I decided to write more in-depth about it while focusing on the model registry.
If you miss the first part of the series, you can read it below.
MLOps Basic Open-Source Tool Series #1: MLflow for Experiment Tracking and Model Management

This newsletter is part of a series introducing open-source tools used in Machine Learning Operations (MLOps). Each series will introduce new tools for different parts of the process. We would combine everything at the end of the series to make a cohesive MLOps project.
We would learn more about the basic concept and how to manage our model with MLFlow Registry.
So, let’s learn about it!
MLFlow for Model Registry
We learned how to install the MLFlow in our previous series, so I would not repeat that part.
In the current newsletter, we would focus on the MLFlow Model Registry concepts and perform hands-on tutorials for several important activities.
If you have followed the previous entry in the series, you might already tried to perform experiment tracking and see the registered model in the MLFlow dashboard, similar to the image below.

You could do many things to improve your model management and registry experience with MLFlow, from manually registering the model to putting a description and fetching the model back into your development environment.
Let’s try various Model Registry API workflows from the MLFlow.
First, let’s review a simple pipeline of registering our model after model training. In this example, we would train a Decision Tree model and register them.
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, f1_score
from mlflow.models import infer_signature
model_name = 'Decision Tree'
RUN_NAME = f'Titanic Classifier Experiment {model_name}'
params = {'max_depth':3, 'min_samples_split':2}
with mlflow.start_run(experiment_id=experiment_id, run_name=RUN_NAME):
model = decision_tree = DecisionTreeClassifier(**params)
model.fit(X_train, y_train) # Train model
predictions = model.predict(X_test) # Predictions
# Calculate metrics
accuracy = accuracy_score(y_test, predictions)
f1 = f1_score(y_test, predictions, average='weighted')
# Log the hyperparameters
mlflow.log_params(params)
# Log the loss metric
mlflow.log_metric(f"{model_name}_accuracy", accuracy)
mlflow.log_metric(f"{model_name}_f1", f1)
# Set a tag that we can use to remind ourselves what this run was for
mlflow.set_tag("Training Info", f"{model_name} model for Titanic")
# Infer the model signature
signature = infer_signature(X_train, model.predict(X_train))
#log the model
model_info = mlflow.sklearn.log_model(
sk_model=model,
artifact_path=f"titanic_{model_name}_model",
signature=signature,
input_example=X_train,
registered_model_name=f"tracking-titanic-{model_name}",)
mlflow.end_run() If you go to your MLFLow dashboard in the model section, you should see something like the image below.

Model version 1 is the first model we registered under that name. If we register another model with the same name, it could be updated into another version.
Selecting the Version lets you see the model details much better.
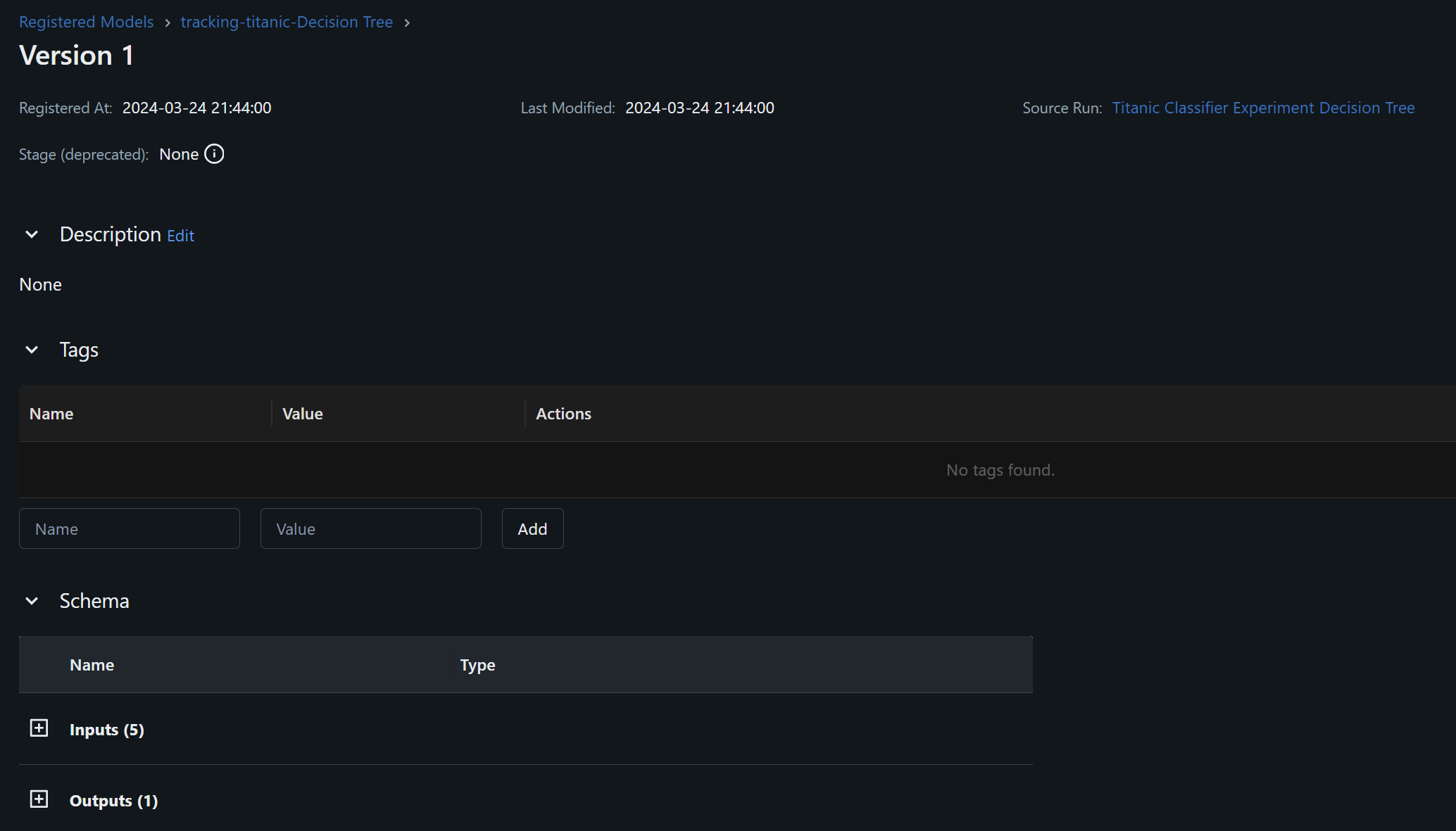
It feels empty as we don’t provide much information besides the name and the schema. Let’s try to provide more details to enrich the model registry.
Tags and Alias
You can use the UI to provide more information, but we would use the API workflow approach to streamline the process better.
First, we can add model Tags with the following code.
from mlflow import MlflowClient
client = MlflowClient()
client.set_registered_model_tag("tracking-titanic-Decision Tree", "task", "classification")
Tags are helpful when you have multiple models registered and only want to get a specific model. Use the Tags in a way that you or the team would understand.
You can also change the model version Tags with the following code.
client.set_model_version_tag("tracking-titanic-Decision Tree", "1", "validation_status", "approved")The version Tags are important to use when you want to provide information on a specific version.
It’s also possible to give an Alias to the model. For example, we give the model Version 1 as “champion”.
client.set_registered_model_alias("tracking-titanic-Decision Tree", "champion", "1")
Additionally, you can delete the Tags and Alias with the following code.
# Delete registered model tag
client.delete_registered_model_tag("tracking-titanic-Decision Tree", "task")
# Delete model version tag
client.delete_model_version_tag("tracking-titanic-Decision Tree", "1", "validation_status")
# delete the alias
client.delete_registered_model_alias("tracking-titanic-Decision Tree", "Champion")Lastly, you can add the model description for each Version with the following code.
client.update_model_version(
name="tracking-titanic-Decision Tree",
version="1",
description="This model is a sample titanic model with decision tree as baseline",
)
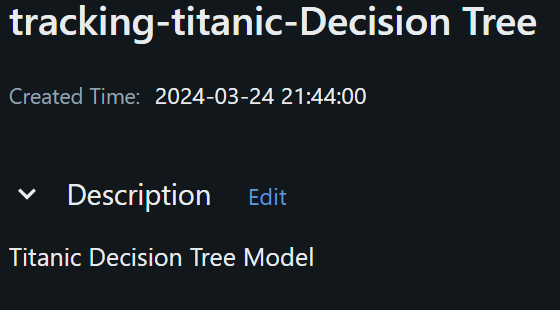
Or do you want to update the whole model description, then you can use the following code.
client.update_registered_model(
name="tracking-titanic-Decision Tree",
description="Titanic Decision Tree Model",
)
Model Fetching
The Model Registry could also function as model fetching. We can always access the model that we have registered and create predictions from that model.
For example, we would fetch the model we previously developed.
import mlflow.pyfunc
model_name = "tracking-titanic-Decision Tree"
model_version = 1
model = mlflow.pyfunc.load_model(model_uri=f"models:/{model_name}/{model_version}")|Then, we would predict our dataset with the following code.
model.predict(X_test)
How easy is that? It’s also possible to fetch the model with the Alias.
alias = 'champion'
champion_version = mlflow.pyfunc.load_model(f"models:/{model_name}@{alias}")
champion_version.predict(data)The result would be the same with the above code. It’s only a matter of how you want to fetch the model.
Conclusion
This is the second part of the MLOps basic series. We have already learned much more in-depth about MLFlow for Model Registry.
We will continue to learn the MLOps basics in the next newsletter and combine everything. So, stay tuned!