
NBD Lite #2: Common Classification Machine Learning Algorithms
Various algorithms that you should know.

Here is your introduction visualization to the most popular and common classification machine learning algorithms🌟

A classification machine learning algorithm is supervised learning where the prediction is a class (category) instead of continuous values.
If we visualize them, classification machine learning works like the below image.

We have input features and the expected outcomes from the dataset we want the algorithm to learn. Using the algorithm, we predict the unseen data. As it’s a classification, the output is a particular class.
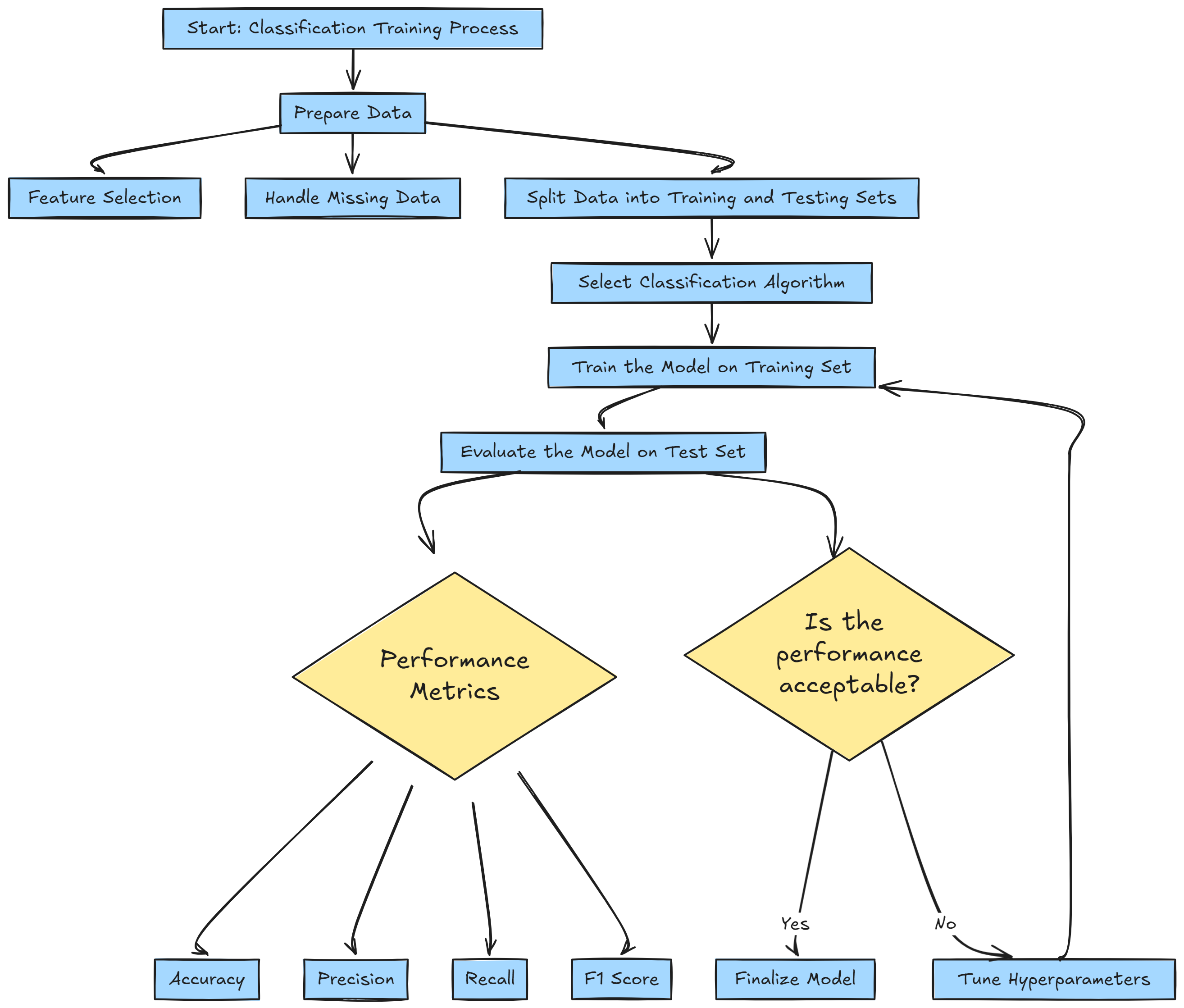
In the machine learning lifecycle, the overall classification training process can be seen in the chart below.
We will discuss them in a separate post, but remember that the machine learning life cycle is an iteration process.
Let’s see the common machine learning algorithms to use and the Scikit-Learn implementation.
1. Logistic Regression
Logistic Regression is a classification machine learning that is commonly used for binary classification.
The algorithm uses a logistic function (the sigmoid function) to model the data patterns and provide their probabilities. Then, a threshold (typically 0.5) is decided as a decision boundary (class to predict).
Advantages:
Easy to implement and interpret.
Outputs probabilities, which are useful in many applications.
Performs well when the classes are linearly separable.
Disadvantages:
It cannot handle non-linear relationships.
Sensitive to multicollinearity (high correlation between features).
2. Decision Tree
Decision Tree is a classifier algorithm that uses a flowchart-like structure to split data based on the data. It would then make decisions by going down the tree until it reaches a terminal node (leaf) to make a decision.
Usually, the splitting decision uses the Gini Index or Entropy.
Advantages:
Easy to interpret visually.
Able to handle both categorical and numerical features.
Can handle complex datasets with non-linear decision boundaries.
Disadvantages:
Prone to overfitting (creates overly complex trees) by learning the noise.
Unstable with small variations in the data, as slight changes can result in a different tree structure.

3. Random Forest
Random Forest is an ensemble learning method (combination of many models) that creates a "forest" of decision trees. Each tree is built from a different random subset of the data (columns and rows were sampled), and the final prediction is based on the majority vote for classification.
Advantages:
It handles large datasets well and is not easy to overfit.
Like the Decision Tree, it could handle both categorical and numerical features.
It also could handle non-linear datasets.
Disadvantages:
Requires more memory and computational power compared to simpler models.
It can be slow for real-time predictions with large forests.

4. Gradient Boosting
Gradient Boosting is an ensemble method in which models are built sequentially. Each new model focuses on the misclassified occurrence and then tries to fix the problem for the next one.
Advantages:
Having superior performance metrics.
Can handle missing values, outliers, and a mix of data types.
Disadvantages:
Computationally expensive and can take a long time to train.
Prone to overfitting if not properly tuned.

5. Naive Bayes
Naive Bayes is a linear probabilistic classifier that applies Bayes’ Theorem, assuming that the input features are independent given the class label. It’s often used in text classification and works well for high-dimensional datasets.
Advantages:
Simple to implement and fast to train.
Works well with high-dimensional data, such as text or image classification.
Performs well on small datasets.
Disadvantages:
Assumes independence between features, which is rarely true in practice.
Not ideal for continuous features unless they are discretized (into categorical).

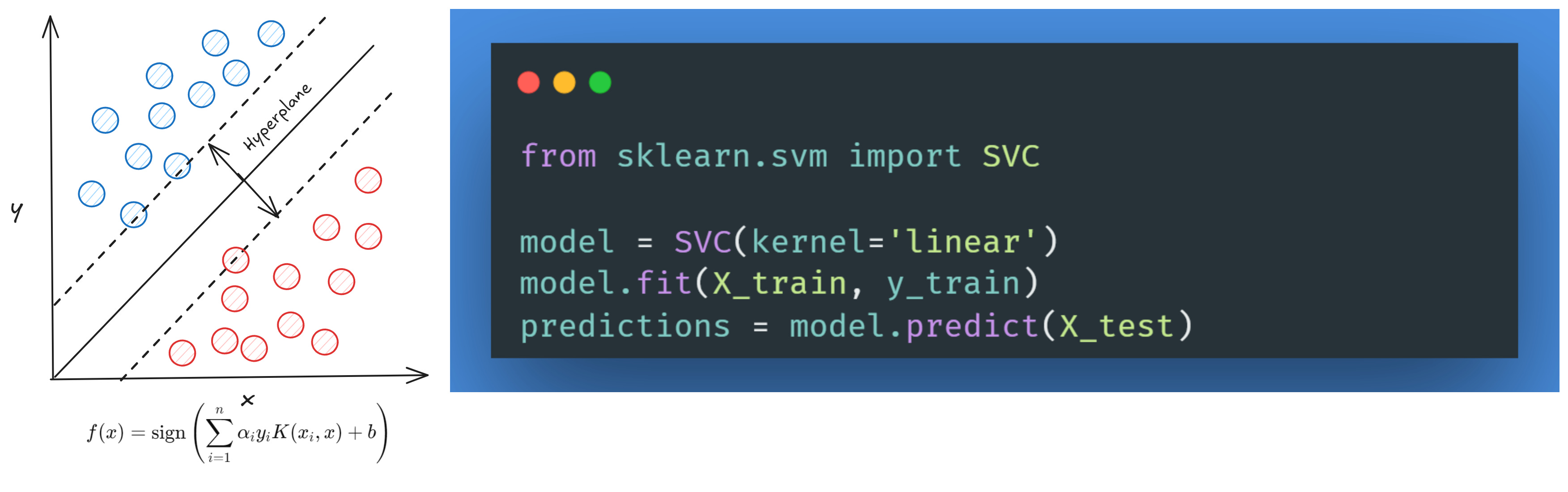
6. Support Vector Machine (SVM)
Support Vector Machine (SVM) is a machine learning algorithm that tries to find the hyperplane that best separates the data into different classes. It can work with non-linear data by applying kernel tricks to map data into higher dimensions.
Advantages:
Effective in high-dimensional (a lot of features) spaces.
Works well when there is a clear margin of separation.
Can use kernel functions to handle non-linear data.
Disadvantages:
It is not suitable for very large datasets due to high computational complexity.
Requires careful parameter tuning (e.g., choice of kernel, regularization).
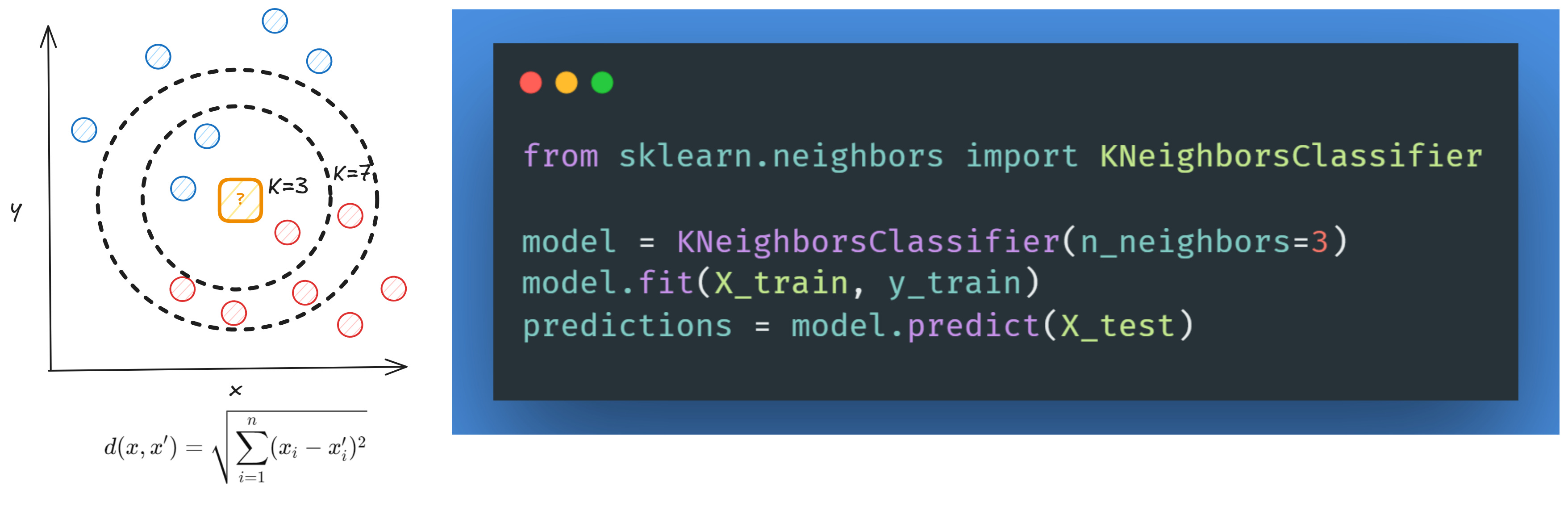
7. K-NN
K-Nearest Neighbors (K-NN) is a classification machine learning algorithm that classifies an input based on the majority class of its “K” nearest neighbours in the feature space. It relies on metrics like Euclidean distance to find these neighbours and the “K” values.
Advantages:
Simple to understand and implement.
No training phase, just a stored dataset.
Good for low-dimensional data.
Disadvantages:
Computationally expensive for large datasets (especially in high dimensions).
Sensitive to the scale of the data because it is based on distance (requires normalization).
8. Isolation Forest
Isolation Forest is a special classification algorithm as it belongs to the one-class classification algorithm. It’s often used as an anomaly detection algorithm because it works by isolating data points. It constructs trees randomly and isolates outliers quickly because they require fewer splits to be isolated.
Advantages:
Effective in detecting outliers and anomalies in high-dimensional datasets.
Fast and scalable, particularly with large datasets.
Disadvantages:
Not effective when the dataset has few anomalies or outliers.

9. Neural Network (NN)
Neural networks (specifically Multi-Layer Perceptrons, or MLPs) are algorithms inspired by human brain neural networks for learning data patterns. MLPs consist of multiple layers of nodes connected feed-forward, each representing a neuron.
Advantages:
Can model complex non-linear relationships between features and target classes.
Versatile and can handle different tasks (classification, regression, etc.).
Scalable to large datasets and can approximate any continuous function.
Disadvantages:
Requires a lot of data to generalize well.
Computationally expensive and requires proper tuning of many hyperparameters (e.g., number of layers, learning rate, etc.).

That’s all for today! I hope this helps you imagine how the classifier algorithm works. In later posts, I will explain the algorithms in detail and provide technical tips for using them.
Any classification algorithm that you really like? Let’s discuss it together!
👇👇👇