
Python Packages for Data Cleaning - NBD Lite #36
Easily clean your data with these Python packages

Many would think that data science work is exclusive to developing machine learning models and evaluating technical metrics.
While it isn’t wrong, the job responsibility is so much more. Data scientists need to work on data collection, cleaning, analysis, data understanding, etc.
Which task do data scientists spend their time on the most, then? According to a survey by CrowdFlower, data scientists spend 80% of their time cleaning data.
This is not surprising because our data science project depends on how clean our data is.
However, there are methods to shorten data cleaning processing times by employing data cleaning packages.
What are these packages, and how do they work? Let us learn together.
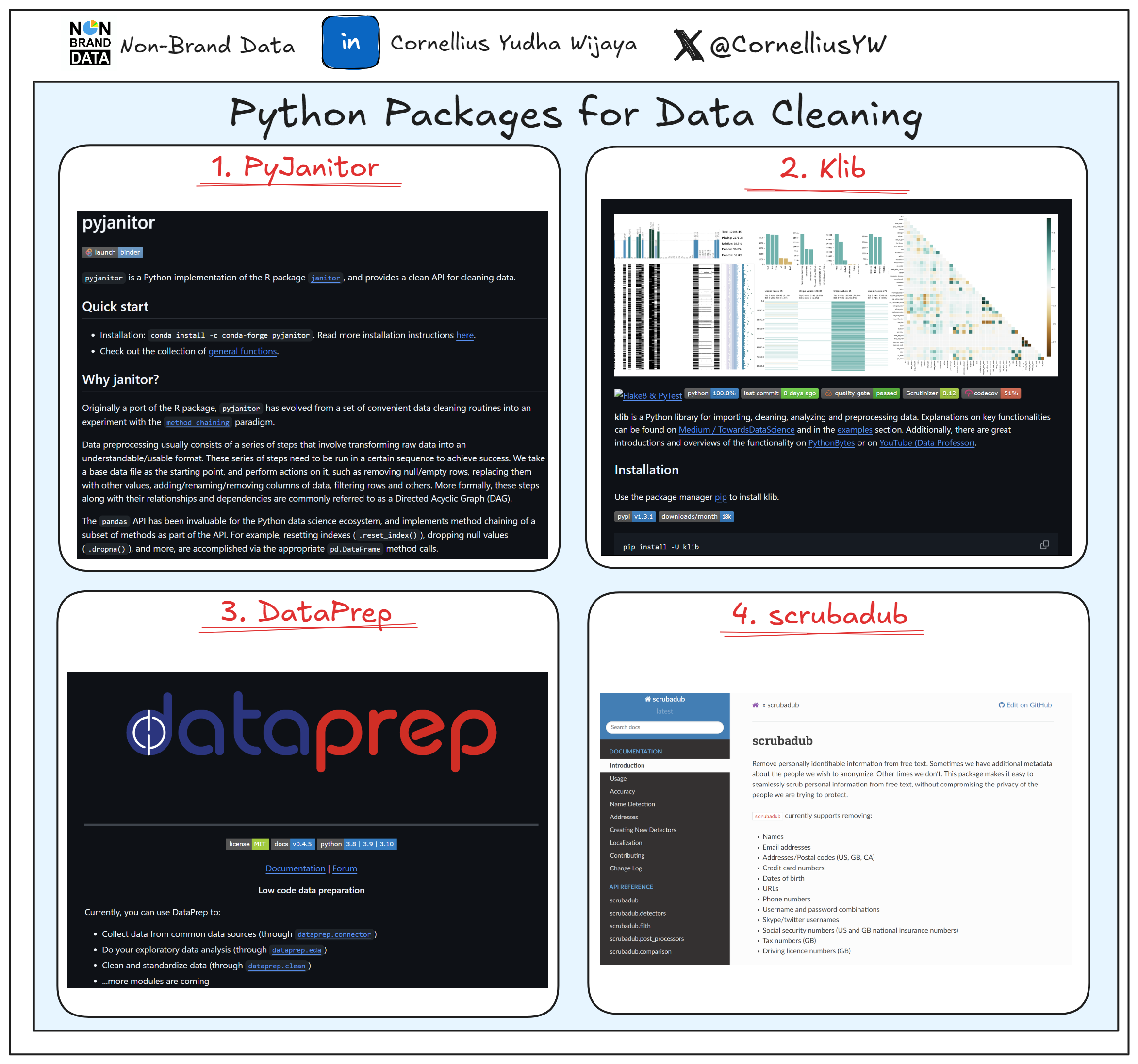
1. Pyjanitor
Pyjanitor is an implementation of the Janitor R package to clean data with chaining methods on the Python environment. The package is easy to use, with an intuitive API connected directly to the Pandas package.
Historically, Pandas already provide a lot of useful data cleaning functions, such as dropna dropping the null values and to_dummies for categorical encoding.
On the other hand, Pyjanitor enhances Panda’s cleaning API competence instead of replacing it. How does Pyjanitor work? Let’s try to implement Pyjanitor in our data-cleaning process.
As a project example, I would use the dataset Coffee Meet Bagel review from Kaggle.
import pandas as pd
review = pd.read_csv('data_review.csv')
review.info()
Our dataset has 11 columns with object and numerical data. At a glance, some of the data seem missing, and the column names are not standardized. Let’s try to clean up the dataset with Pandas and Pyjanitor.
Before we start, we need to install the Pyjanitor package.
pip install pyjanitorWhen you have finished installing the package, we only need to import the package, and the API function is immediately available via Pandas API. Let’s try the Pyjanitor package with our sample dataset.
import janitor
jan_review = review.factorize_columns(column_names=["userName"]).expand_column(column_name = 'reviewCreatedVersion').clean_names()In the code example above, The Pyjanitor API did the following actions:
Factorize the userName column to convert the categorical into numerical data (
factorize_columns),Expand the reviewCreatedVersion column or One-Hot Encoding process (
expand_column),Clean the column’s name by converting them to lowercase, then replace all spaces with underscores (
clean_names).
The above is an example action we could take with Pyjanitor. There is so much more you could do with Pyjanitor, and I will show you in the image below.

Furthermore, the chain method also works with Panda’s original API. You could combine both to accomplish the clean data you want.
2. Klib
Klib is an open-source Python package for importing, cleaning, and analyzing. It is a one-stop package used for easily understanding your data and preprocessing. The package is good for assessing your data using intuitive visualization and easy-to-use APIs.
This article only discusses data cleaning, so let us focus on the data cleaning API. If you want to explore further with Klib, you could check the following article.
For data cleaning, Klib relies on the data_cleaning API to automatically clean the data frame. Let’s try the API with the dataset example. First, we need to install the package.
pip install klibAfter the installation, we would pass the dataset to the data_cleaning API.
import klib
df_cleaned = klib.data_cleaning(review)
The above function produces the data cleaning information done to our dataset example. Klib data_cleaning procedure follow the current steps:
Column names cleaning,
Dropping empty and virtually empty columns,
Removes single cardinal columns,
Drops duplicate rows,
Memory reduction.
3. DataPrep
DataPrep is a Python Package created for data preparation where the main task includes:
Data Exploration
Data Cleaning
Data Collection
For the article’s purpose, I will focus on the DataPrep data Cleaning APIs. However, if you are interested in the DataPrep package, you can read my explanation in the article below.
DataPrep Cleaning offers more than 140 APIs for data cleaning and validation. The GIF below shows all the available APIs.
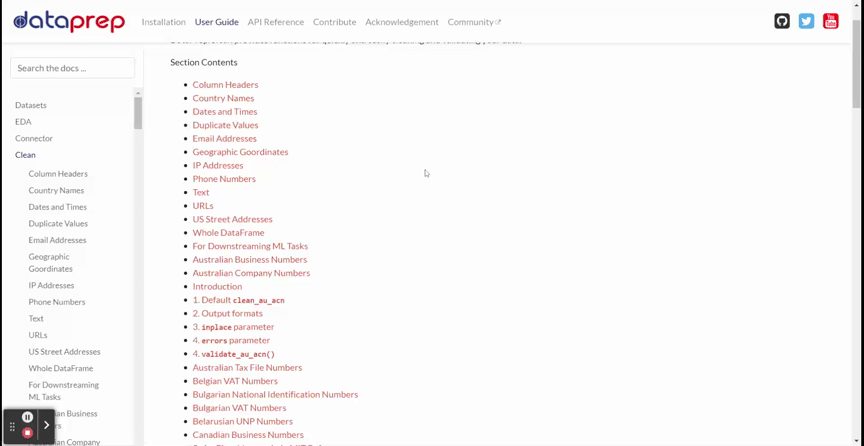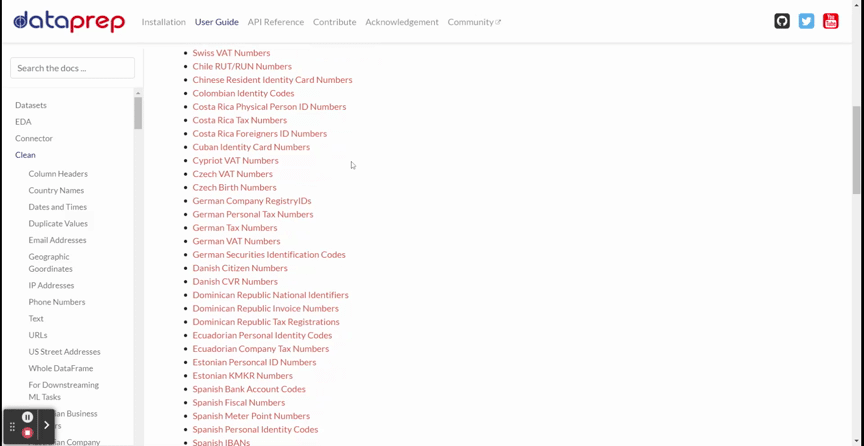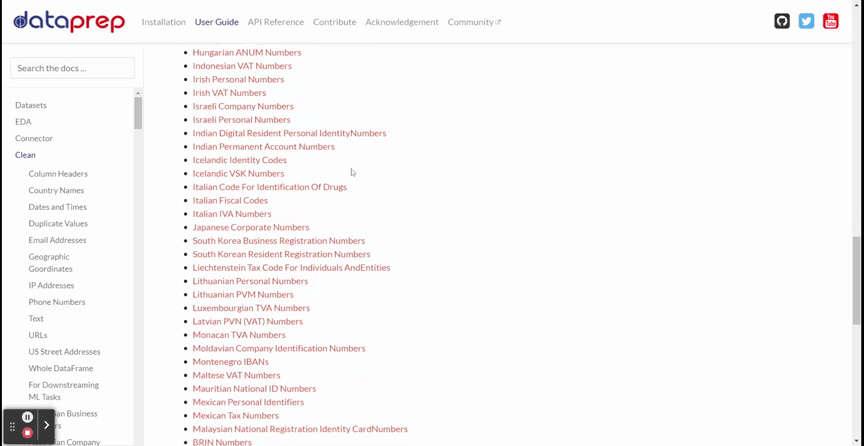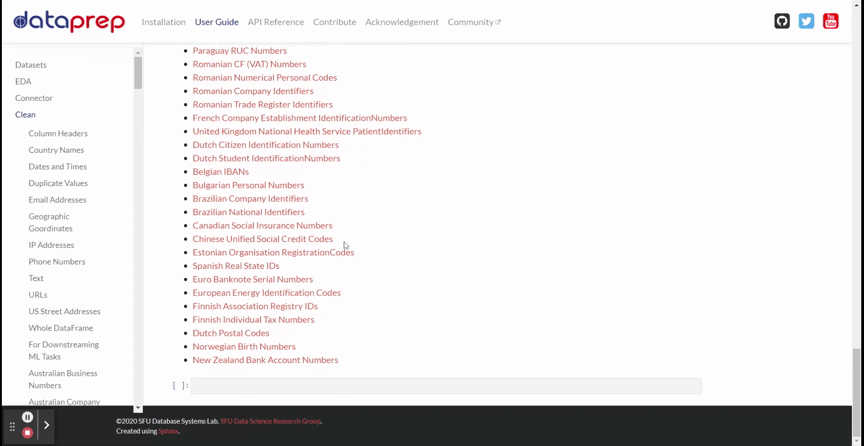
The GIF above shows various APIs to use, such as Column Headers, Country Names, Dates and Times, and many more. All the APIs you need for the cleaning are there.
If you are not sure what to clean, you can always rely on the clean_df API from DataPrep automatically cleans your data and lets the package infer what you need. Let’s try the API to learn more about it.
First, we need to install the DataPrep package.
pip install dataprepAfter the package installation, we could apply the clean_df API in our previous dataset example.
from dataprep.clean import clean_df
inferred_dtypes, cleaned_df = clean_df(review)The API would have two outputs: the inferred data type and the cleaned DataFrame. The process also produces the data frame cleaning summary.

The report above provides information on what data types were processed, the column headers that were cleaned, and the memory reduction.
If you feel the cleaning is enough, you could use the cleaned data frame for your next step. If not, you could play around with the available cleaning API.
4. scrubadub
Scrubadub is an open-source Python package to remove personally identifiable information from text data.
Scrubadub works by removing the detected personal data and replacing it with a text identifier such as {{EMAIL}} or {{NAME}}.
Currently, Scrubadub only supports removing the following personal data:

Let’s try to clean our sample dataset with Scrubadub. First, we need to install the package.
pip install scrubadubAs we saw in the image above, we could remove various personal data, such as names and email addresses, using Scrubadub.
Let’s use a data sample containing personal information such as name, email, and personal email.
review['replyContent'].loc[24947]
The data contains the name and email data we want to remove. Let’s use the Scrubadub to do it.
sample = review['replyContent'].loc[24947]
scrubadub.clean(sample)
The clean data has the email data removed and replaced by identifier {{EMAIL}}. However, we still have the name data identified. How could Scrubadub remove the name?
To enhance the Scrubadub name identifier, we need to add the name detection improvement from other packages.
For this example, let’s add the detector from TextBlob.
scrubber = scrubadub.Scrubber()
scrubber.add_detector(scrubadub.detectors.TextBlobNameDetector)
scrubber.clean(sample)
Now, the name is removed and replaced by the {{NAME}} identifier. You could explore the package documentation to understand Scrubadub better.
Those are all my top Python packages for data cleaning.
Are there any more things you would love to discuss? Let’s talk about it together!
👇👇👇
