
Random Forest Feature Importance Explained

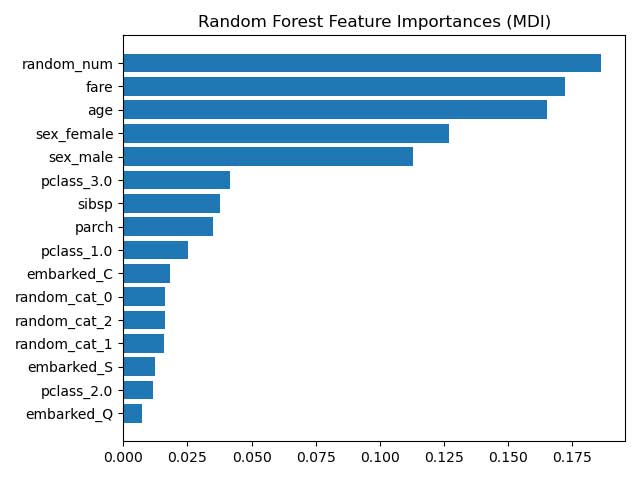
Random Forest is a popular ensemble method to use. It’s popular because it gives a great result and provides feature importance for machine learning interpretability.
But what are Random Forest feature importances and the calculation intuitive behind them?
Random Forest Classifier in the Scikit-Learn using a method called impurity-based feature importance. It is often called Mean Decrease Impurity (MDI) or Gini importance.
Mean Decrease Impurity is a method to measure the reduction in an impurity by calculating the Gini Impurity reduction for each feature split. Impurity is a combination of the existing label on the node; the more heterogenous the split, the more impure the node was.
In the case of Random Forest, the feature MDI is calculated as the average of the impurity decrease for that feature over all the trees in the forest.
The MDI is calculated as follows:
Train a random forest model
For each node of each tree in the forest, compute the impurity of the node before and after the split based on a specific feature.
Compute the weighted sum of the impurity decreases over all nodes that split on the feature. The weight is the proportion of observations that belong to that node.
Average the weighted impurity decrease over all trees in the forest to get the MDI for the feature.
Normalized all the MDI features so that the sum of all scores equals 1.
If we interpret the Random Forest features importance, the higher the MDI score, the more important the features as it brings the most impurity reduction across the trees.
However, there is a caveat on the MDI method. MDI bias toward continuous features with many possible splits and bias toward categorical features with high cardinality.
That is all for today, thank you for subscribing, and let’s meet on the comment.