
Refining Dataset Labels for Superior ML Model
Your Machine Learning Model only as good as the given labels


I want to discuss issues that might rarely be addressed when we develop a supervised machine learning model but is an essential aspect—the label.
In the real world, the label definition comes from the meeting between business stakeholders and data professionals. The label should represent what the business wants to solve but something that should also exist in the whole pipeline.
The label is necessary to ensure the validity of our machine learning model, which is why data scientists are required to manage the label well. This also includes identifying the bad label that might affect our model.
My experience with bad labels affecting the whole model's performance inspired me to write this newsletter.
In this newsletter, I want to show a short tutorial on identifying bad labels with the help of Python Package Cleanlab.
Let’s get into it.
Preparation
For this example, I would use the Titanic train dataset for the tutorial. The dataset contains ‘Survived’ labels that indicate whether the passenger survived the Titanic incident. However, I would not use all the columns; instead, only the numerical columns I deemed necessary.
import pandas as pd
df = pd.read_csv('train.csv')
df = df[['Survived', 'Pclass', 'SibSp', 'Parch']]Additionally, we would install the Cleanlab packages with the following code.
pip install cleanlab[all]With the preparation ready, we would try to identify the label issues and develop a better classifier model.
Label Issue Identification
Cleanlab tries to estimate labels to be potentially incorrect by using probabilistic prediction from our model. However, the prediction should come from out-of-sample probabilities, which is a prediction that comes from data not used for training.
For example, we can use K-fold cross-validation to acquire out-of-sample prediction probabilities. Let’s try to use them and see if our dataset contains label issues.
In our example, we would use the Logistic Regression model as the baseline model.
from sklearn.model_selection import cross_val_predict
from sklearn.linear_model import LogisticRegression
num_crossval_folds = 5
pred_probs = cross_val_predict(
model,
df.drop('Survived', axis =1),
df['Survived'],
cv=num_crossval_folds,
method="predict_proba",
)With the prediction probability, let’s use Cleanlab to identify the potential label issues. First, let’s use the Datalab to get the whole report.
from cleanlab import Datalab
lab = Datalab(data=df, label_name="Survived")
lab.find_issues(pred_probs=pred_probs)
lab.report() 
We can see that our dataset contains label issues, which is around 224 out of 891 labels. It’s close to a quarter of our data, which isn’t good.
Additionally, Datalab also found an outlier issue with our dataset.

In both cases, Datalab provides how severe the issues are and the data examples that are affected by these issues.
If you want to get the dataset row information that contains label issues, you can use the following code.
from cleanlab.filter import find_label_issues
ranked_label_issues = find_label_issues(
labels=df['Survived'], pred_probs=pred_probs, return_indices_ranked_by="self_confidence"
)
ranked_label_issues
You can get which rows have the most severe and minor severity issues.
Let’s try to see the model performance differences between our current dataset and the clean dataset.
Machine Learning Comparison
We would split the dataset to follow the best practices of machine learning development.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df.drop('Survived', axis =1), df['Survived'], random_state = 42)Next, we would see the whole model performance with the following code.
from sklearn.metrics import classification_report
model.fit(X_train, y_train)
preds = model.predict(X_test)
print(classification_report(y_test, preds))
We achieved 71% accuracy, although the survived class 1 wasn’t done well.
Let’s use Cleanlab to enhance our current classification model to address the label issues.
import cleanlab
cl = cleanlab.classification.CleanLearning(model, seed=42)
_ = cl.fit(X_train, y_train)In the code above, we pass our model to the Cleanlab ClearLearning wrapper so our model can learn from the dataset with fixed label issues.
The result can be seen in the image below.
clean_preds = cl.predict(X_test)
print(classification_report(y_test, clean_preds))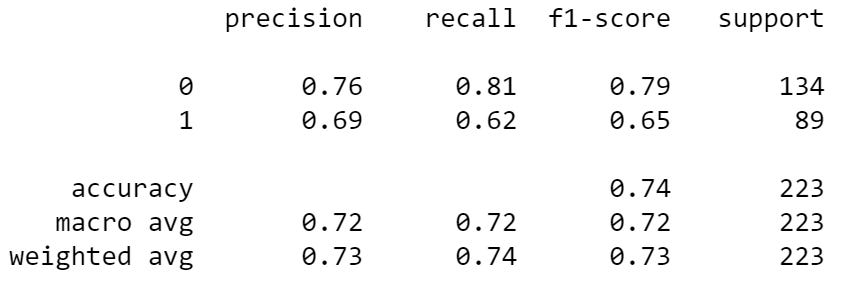
As you can see, there is an improvement in the whole model performance, especially for Class 1. We might want to try another model algorithm to see the differences.
Overall, cleaning label issues have proven to help improve our model metrics.
If you are curious which label the classifier identifies as an issue, you can examine them using the following code.
# See the label quality for every example, which data has issues, and more.
cl.get_label_issues().head()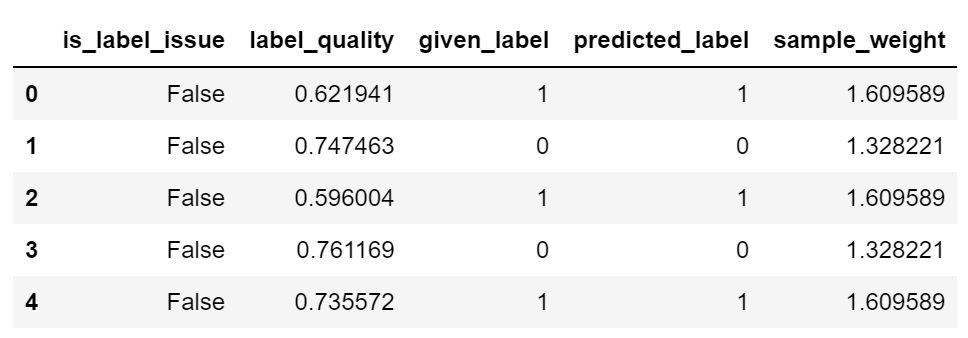
Try to play around with Cleanlab, as I am sure it would be beneficial for any data scientist to fix your label issues.

Conclusion
Data label issues are a problem that is rarely addressed during machine learning development. The issues could occur during any point of data collection and problem identification. In this newsletter, we discuss how to use Cleanlab to identify label issues and use the package to fix our classifier model concerning the issues.
Thank you, everyone, for subscribing to my newsletter. If you have something you want me to write or discuss, please comment or directly message me through my social media!