
Speed up your Pandas Processing with Swifter
Don’t let your data processing taking you too long

Don’t let your data processing taking you too long

As a Pythonist Data Scientist, your daily job would involve a lot of data processing and feature engineering using the Pandas package. From analyzing data to create a new feature to gain insight, forcing you to execute many different codes repeatedly. The problem is the bigger your data, the longer time to finish running each line of code.
In this article, I want to show you a simple package to speed up your Pandas processing called Swifter. Let’s just get started.
Swifter
Swifter is a package that tries to efficiently apply any function to a Pandas Data Frame or Series object in the quickest available method. It is integrated with the Pandas object so that we would use this package only with a Pandas object such as Data Frame or Series.
Let’s try to see Swifter in action. For preparation, we need to install the Swifter package.
#Installing Swifter via Pippip install swifter#or via condaconda install -c conda-forge swifterIn case you have not possessed the latest Pandas package, it is suggested to update the package into the newest version. This is because Pandas extension api used in the Swifter module is a recent addition to pandas.
#Update the Pandas package via pippip install -U pandas#or via condaconda update pandasWhen all the required packages ready, we could proceed to try Swifter. In this article, I would use the Reddit comment dataset from Kaggle. From here, we import all the packages to our notebook and read the dataset from CSV as usual.
#Import the packageimport pandas as pdimport swifter#read the datasetdf = pd.read_csv('r_dataisbeautiful_posts.csv')
This is our dataset. Now, let’s say I want to multiply the score by two and subtract the score by one (This is just a random equation I used here). Then I would put it in another column. In this case, I could use the apply function from the Pandas object attribute.
%time df['score_2_subs'] = df['score'].apply(lambda x: x/2 -1)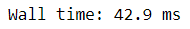
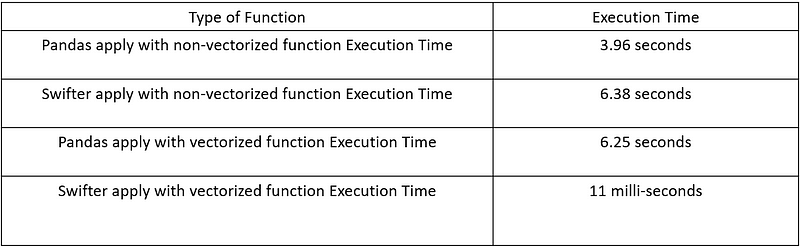
The time to execute the function to each data takes around 42.9 ms for an apply attribute by Pandas. This time, we would use Swifter and see how much time it take to execute the function.
#When we importing the Swifter package, it would integrated with Pandas package and we could use functional attribute from Pandas such as apply%time df['score_2_swift'] = df['score'].swifter.apply(lambda x: x/2 - 1)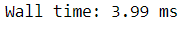
As we can see above, Swifter processes the data way faster compared to the normal Pandas apply function.
Vectorized Function for Swifter
From the documentation, it is stated that Swifter could apply function a hundred times faster than Pandas function. This, however, only applied if we are using a vectorized form of function.
Let’s say I create a function that evaluates the num_comments and score variable. When the comment count is zero, I will double the score. While it’s not, the score would stay the same. Then I would create a new column based on that.
def scoring_comment(x): if x['num_comments'] == 0: return x['score'] *2 else: return x['score']#Trying applying the function using Pandas apply%time df['score_comment'] = df[['score','num_comments']].apply(scoring_comment, axis =1)
It takes around 3.96 seconds to execute the function. Let’s see the performance if we are using Swifter.
%time df['score_comment_swift'] = df[['score', 'num_comments']].swifter.apply(scoring_comment, axis =1)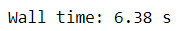
As we can see above, it takes much longer using Swifter compared to the regular Pandas apply function. This is because Swifter with non-vectorized function would implement dask parallel processing, not relying on the Swifter processing itself. So, how is the performance if we change the function to the vectorized function? Let’s try it.
Import numpy as np#Using np.where to implement vectorized functiondef scoring_comment_vectorized(x): return np.where(x['num_comments'] ==0, x['score']*2, x['score'])#Trying using the normal Pandas apply%time df['score_comment_vectorized'] = df[['score', 'num_comments']].apply(scoring_comment_vectorized, axis =1)
It takes around 6.25 seconds using the normal apply function to execute our vectorized function. Let’s see the performance using Swifter.
%time df['score_comment_vectorized_swift'] = df[['score', 'num_comments']].swifter.apply(scoring_comment_vectorized, axis =1)
The execution time now takes only 11 ms with the vectorized function, which saves so much time compared to the normal apply function. This is why it is advisable to use the vectorized function when we are processing data with Swifter.
If you want to keep track of the execution time that just happen, I will give you the overall summary in the table below.
Conclusion
I just show you how Swifter could speed up your Pandas Data Processing. Swifter is works best when we use a vectorized function instead of a non-vectorized function. If you want to know more about the Swifter and the available API, you could check the documentation.