
Statistik Dasar untuk Data Scientist — Part 1
Saya dulu pernah membaca jawaban user di Quora tentang apakah yang sebenanrya dibutuhkan untuk memasuki dunia Data Science. Salah satu…

Saya dulu pernah membaca jawaban user di Quora tentang apakah yang sebenarnya dibutuhkan untuk memasuki dunia Data Science. Salah satu jawaban yang selalu saya ingat adalah kita membutuhkan:
Sedikit kemampuan Programming
Sedikit kemampuan Visualisasi
Sedikit kemampuan Komunikasi
Sedikit kemampuan Statistik
Sedikit kemampuan Bisnis
Kenapa sedikit? karena kita hanya mengambil sebagian kecil dari ilmu tersebut untuk kita terapkan kedalam permasalahan di dunia Data Science. Walau sedikit, kemampuan tersebut tetap menjadi titik krusial yang perlu dipelajari.
Akan tetapi, saya sering melihat banyak orang ingin memasuki dunia Data Science tetapi melewatkan tahapan untuk memahami statistik yang sebenarnya diperlukan. Oleh karena itu, saya ingin sedikit menulis konsep-konsep statistik yang penting untuk dipahami serta contoh pengunaanya.
Populasi dan Sampel
Populasi adalah keselurahan individu atau benda yang ingin kita teliti atau yang kita tertarik ingin kita ketahui. Walau begitu, hampir mustahil untuk mengukur populasi secara keseluruhan. Oleh karena itu, kita mempunyai konsep yang dinamakan Sampel. Sampel bisa dikatakan perwakilan dari Populasi yang merepresentasikan populasi.
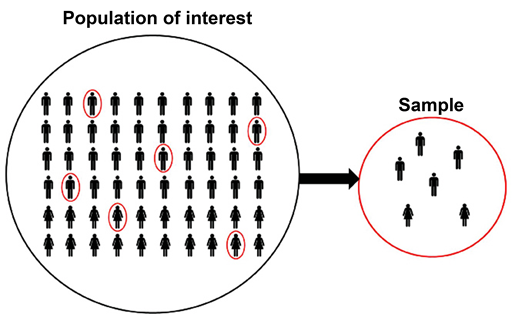
Salah satu tujuan dari pengunaan ilmu statistik adalah untuk mengetahui Parameter populasi (seperti Mean, Median, dll.), tetapi kita menggunakan sampel untuk merepresentasikan populasi sehingga secara lebih tepat yang kita selalu lakukan perhitungan terhadap data kita disebut dengan Statistik sampel. Karena itu juga, Parameter populasi ini biasanya tidak pernah diketahui dan kita menggunakan sampel statistik untuk memperkirakan parameter populasi ini.
Istilah penting: Populasi, Sampel, Parameter Populasi, Statistik Sampel
Statistik Deskriptif
Statistik Deskrptif adalah cabang dari statistik untuk mendeskripsikan dan merangkum data. Contoh hal umum yang biasa kita lakukan di dalam tipe statistik ini seperti pembuatan graph, dan menghitung berbagai macam pengukuran data seperti Mean. Ada 2 cara secara umum untuk mendeskripsikan data, yaitu:
a. Measures of Central Tendency
Yaitu cara untuk mendeskripsikan posisi titik tengah dari distribusi frekuensi suatu kelompok data. 3 cara paling umum untuk digunakan adalah menggunakan:
Mean
Mean adalah jumlah dari seluruh data continous (numerikal) dibagi dengan jumlah data yang ada. Mean adalah measure of central yang paling sering digunakan untuk data numerikal. Jika kita berbicara tentang populasi, maka lambang Mean yang biasa digunakan adalah μ sedangkan pada sampel adalah x̄.
Median
Median adalah nilai tengah dari suatu data numerikal yang diurutkan. Jika jumlah data kita ganjil, maka nilai median tepat berada di tengah-tengah dari data. Jika jumlah data kita genap, maka nilai median kita berada di antara kedua nilai yang berada di tengah; sebagai contoh jika kita mempunyai data 1,1,2,3,3,4,4,5 maka nilai median kita adalah 3 karena kita mempunyai 8 data sehingga nilai titik tengahnya berada di posisi ke-4 (nilai 3) dan ke-5 (nilai 3) dan lebih tepatnya lagi data di kedua posisi ini ditambahkan lalu dibagi 2.
Median lebih sering digunakan jika Mean tidak mampu menjelaskan data kita dengan baik, sehingga diperlukan pengukuran titik tengah menggunakan pengukuran lain.
Mode
Mode atau Modus adalah suatu data categorical (bukan numerikal) atau data continous yang dapat dihitung dimana frekuensi dari data tersebut paling besar. Dengan kata lain adalah data yang paling sering muncul.
Kita menggunakan Mode jika data kita adalah data categorical atau data numerikal yang kita anggap sebagai suatu data categorical.
b. Measures of Spread
Yaitu cara untuk mendeskripsikan data kita dengan menjelaskan seberapa menyebar data kita. Yang sering digunakan adalah:
Range
Range adalah perbedaan antara data numerikal terkecil hingga data terbesar. Tidak banyak informasi yang bisa kita ketahui selain mengetahui perbedaan besar data kita.

Quartile
Quartile adalah nilai yang membagi data menjadi 4 bagian. Bagian yang terbagi disebut dengan Quarter. Jika kita menyebut Quartile, maka yang sebenarnya kita acu adalah nilai yang membagi, bukan hasil bagiannya.
Terdapat 3 jenis Quartile pada saat menggunakan metode Quartile, yaitu Q1 (Nilai antara median dengan data terkecil), Q2 (Median), dan Q3 (Nilai antara median dengan terbesar).
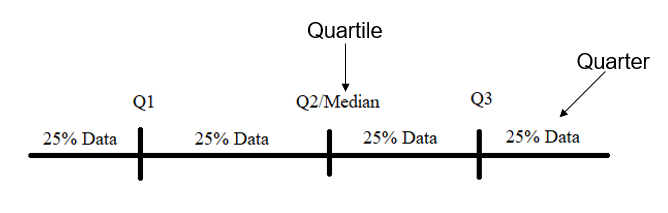
Salah satu pertanyaan yang mungkin diajukan adalah apakah Quartile ini termasuk kedalam data yang berada di Quarter? Jawabannya adalah tergantung dari peraturan metode yang digunakan. Ada yang memasukkan dan ada juga yang tidak.
Quartile sangat berguna karena berhubungan dengan konsep statistik lain yaitu Interquartile Range (IQR) yang sering digunakan untuk mencari outlier (data yang ekstrim). IQR sendiri didapatkan dengan cara mengurangi Q3 dengan Q1 (IQR = Q3 — Q1).
Dengan menggunakan metode IQR, kita bisa menentukan outlier melalui suatu nilai batas yang ditentukan sebagai berikut:
Batas Bawah = Q1–1.5 * IQR
Batas Atas = Q3 + 1.5 * IQR
Data yang kurang dari batas bawah ataupun data yang melebihi batas atas akan disebut dengan outlier.
Variance
Variance adalah pengukuran suatu variabilitas dari data untuk mengetahui seberapa jauh data yang dimiliki tersebar. Rumus dari Variance adalah sebagai berikut:


Variance dihitung berdasarkan total dari setiap data (Xi) dikurangi dengan mean data (x̄). Sedikit perbedaan jika kita berbicara mengenai data pada populasi dan sampel. Pada variance populasi kita membagi data kita dengan seluruh jumlah sampel data (N), sedangkan jika data sampel maka kita membaginya dengan jumlah data yang ada dikurangi 1 (N-1). Ini dilakukan karena data sampel memiliki ketidakpastian dibandingkan populasi sehingga kita memperbesar perhitungan persebaran kita.
Menggunakan variance berarti kita menjelaskan dasar kita melalui titik tengah mean, sehingga variance dapat menjelaskan seberapa tersebar data kita dari mean dan satu sama lainnya. Jika variance kita kecil, maka data kita tersebar dekat dengan nilai mean sedangkan jika nilai variance besar menandakan data kita semakin tersebar jauh dari mean dan dengan satu sama lain. Selain itu, karena variance melakukan pemangkatan dari data maka data yang semakin jauh nilainya akan semakin dibesarkan sehingga kita bisa memperkirakan seberapa banyak data yang jauh dari mean.
Standard Deviation
Standard deviation adalah measure of spread yang paling sering digunakan karena memberikan informasi yang jelas dan intuitif. Untuk mendapatkan nilai Standard deviation kita hanya perlu melakukan akar kuadrat terhadap variance, sehingga jika dirumuskan adalah:


Standard deviation menggambarkan seberapa berbeda nilai di data kita terhadap mean. Jika menggunakan bahasa sehari-hari, standard deviation adalah nilai plus-minus dari mean ( x̄±𝑠). Selain itu standar deviation juga digunakan di dalam empirical rule atau 68–95–99.7 rule dimana normalnya data kita tersebar sebesar ± 1 * STD (68 % data), ± 2 * STD (95 % data), dan ± 3 * STD (99.7% data). Data yang terletak lebih atau kurang dari batas tersebut menandakan bahwa data tersebut adalah suatu outlier.
Perlu diingat bahwa kita tergantung dengan nilai mean untuk menghitung variance dan standar deviation, sehingga data outlier yang begitu besar akan mempengaruhi pengukuran kedua nilai tersebut. Jika kita merasa data kita tidak baik untuk dijelaskan menggunakan mean, maka median adalah pilihan yang lebih tepat (serta menggunakan quartile).
Istilah penting: Measure of Central Tendency, Mean, Median, Mode, Measure of Spread, Range, Quartile, Quarter, IQR, Outlier, Variance, Standard Deviation, Empirical Rule
Contoh dengan data
Semisal, secara acak saya membuat data gaji 1000 sampel dengan mean 5000 dan standard deviation 1000 seperti yang dapat terlihat pada gambar dibawah:
import random import pandas as pd import seaborn as sns import matplotlib.pyplot as pltrandom.seed(101)data_gaji =[int(random.gauss(5000, 1000)) for num in range(1000)]dfGaji = pd.DataFrame(data_gaji, columns = ['Gaji ($)'])
Data kita merupakan data numerikal, sehingga kita bisa mencoba mendapatkan beberapa informasi dari data tersebut. Beberapa info penting bisa dengan mudah kita dapatkan melalui fungsi yang dimiliki oleh pandas di python.
dfGaji.describe()
Dengan menggunakan metode describe yang dimiliki oleh pandas, kita bisa mendapatkan Mean, Standard Deviation, Nilai Minimum, Nilai Maksimum, Q1, Median, dan Q3 secara bersamaan.
Dengan melihat tabel diatas saja, kita dapat sedikit meraba-raba bagaimana bentuk dari data kita. Data kita memiliki Mean $5024 dan Median $5060 sehingga dapat terlihat bahwa data kita memiliki titik tengah yang hampir sama. Selain itu antara antara nilai Min hingga nilai Max tidak ada nilai yang melompat jauh satu dengan lainnya.
Seperti yang saya jelaskan sebelumnya, kita dapat menggunakan metode quartile dan IQR untuk melihat persebaran data kita. Hal itu dapat divisualisasikan melalui boxplot seperti gambar dibawah.
plt.figure(figsize = (8,8))sns.boxplot(data_gaji)plt.title('Boxplot data gaji', fontsize = 20)plt.annotate('Q1', (np.percentile(data_gaji, 25), 0.4), xytext = (np.percentile(data_gaji, 25), 0.5),arrowprops = dict(facecolor = 'black'), fontsize = 12 )plt.annotate('Q2', (np.percentile(data_gaji, 50), 0.4), xytext = (np.percentile(data_gaji, 50), 0.5),arrowprops = dict(facecolor = 'black'), fontsize = 12 )plt.annotate('Q3', (np.percentile(data_gaji, 75), 0.4), xytext = (np.percentile(data_gaji, 75), 0.5),arrowprops = dict(facecolor = 'black'), fontsize = 12 )IQR = np.percentile(data_gaji, 75) - np.percentile(data_gaji, 25)batas_bawah = np.percentile(data_gaji, 25) - (1.5 * IQR)batas_atas = np.percentile(data_gaji, 75) + (1.5 * IQR)plt.annotate('Batas bawah',(batas_bawah+50, 0.2), xytext = (batas_bawah, 0.35) ,arrowprops = dict(facecolor = 'blue'), fontsize = 12 )plt.annotate('Batas atas', (batas_atas-100, 0.2), xytext = (batas_atas, 0.35),arrowprops = dict(facecolor = 'red'), fontsize = 12 )plt.annotate('Outlier', (min(data_gaji), 0.04), xytext = (min(data_gaji), 0.2),arrowprops = dict(facecolor = 'green'), fontsize = 12 )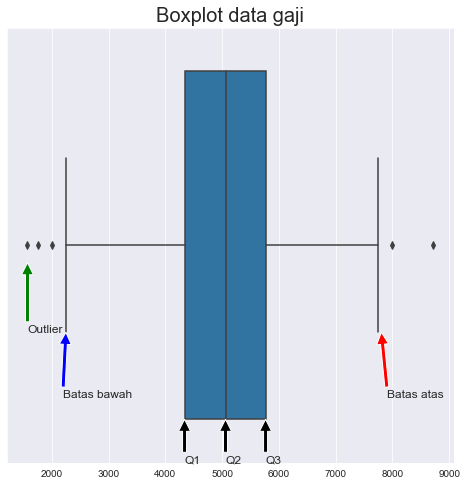
Boxplot diatas menunjukkan bagaimana data kita tersebar. Dapat terlihat bahwa antara Q1 hingga Q3 (atau 50% data) tersebar hanya dia antara $4000an hingga $6000an dengan 50% data yang lain tersebar di luar dari itu. Dengan menggunakan metode IQR juga kita mampu mendapatkan batas bawah dan atas untuk membedakan data mana yang termasuk outlier (ditandakan dengan titik hitam).
Selain itu, melalui standard deviation juga kita bisa melihat bahwa data kita tersebar sebesar $1034 dari mean. Dengan menggunakan Empirical rule sebelumnya, kita bisa memperkirakan persebaran data kita seperti gambar dibawah
plt.figure(figsize = (8,8))sns.distplot(data_gaji)plt.axvline(x = np.mean(data_gaji), ls = '--', c ='red')plt.axvline(x = np.mean(data_gaji) - np.std(data_gaji), ls = '--', c = 'blue')plt.axvline(x = np.mean(data_gaji) + np.std(data_gaji), ls = '--', c = 'blue')plt.axvline(x = np.mean(data_gaji) - 2*np.std(data_gaji), ls = '--', c = 'green')plt.axvline(x = np.mean(data_gaji) + 2*np.std(data_gaji), ls = '--', c = 'green')plt.axvline(x = np.mean(data_gaji) - 3*np.std(data_gaji), ls = '--', c = 'black')plt.axvline(x = np.mean(data_gaji) + 3*np.std(data_gaji), ls = '--', c = 'black')plt.annotate('Mean', (np.mean(data_gaji), 0.0004), xytext = (np.mean(data_gaji), 0.00045),arrowprops = dict(facecolor = 'red'), fontsize = 12 )plt.annotate('1 * STD', ((np.mean(data_gaji) - np.std(data_gaji)), 0.0004), xytext = ((np.mean(data_gaji) - np.std(data_gaji)), 0.00045),arrowprops = dict(facecolor = 'blue') )plt.annotate('1 * STD', ((np.mean(data_gaji) + np.std(data_gaji)), 0.0004), xytext = ((np.mean(data_gaji) + np.std(data_gaji)), 0.00045),arrowprops = dict(facecolor = 'blue') )plt.annotate('2 * STD', ((np.mean(data_gaji) - 2*np.std(data_gaji)), 0.0004),xytext = ((np.mean(data_gaji) - 2*np.std(data_gaji)), 0.00045),arrowprops = dict(facecolor = 'green') )plt.annotate('2 * STD', ((np.mean(data_gaji) + 2*np.std(data_gaji)), 0.0004), xytext = ((np.mean(data_gaji) + 2*np.std(data_gaji)), 0.00045),arrowprops = dict(facecolor = 'green') )plt.annotate('3 * STD', ((np.mean(data_gaji) - 3*np.std(data_gaji)), 0.0004),xytext = ((np.mean(data_gaji) - 3*np.std(data_gaji)), 0.00045),arrowprops = dict(facecolor = 'black') )plt.annotate('3 * STD', ((np.mean(data_gaji) + 3*np.std(data_gaji)), 0.0004),xytext = ((np.mean(data_gaji) + 3*np.std(data_gaji)), 0.00045),arrowprops = dict(facecolor = 'black') )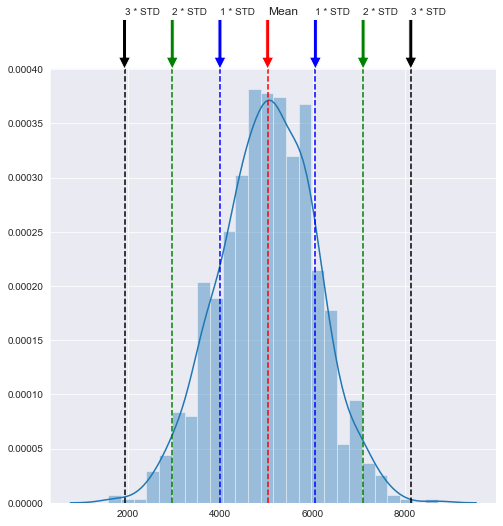
1*STD adalah 68% data kita yang berada di antara mean ± 1 * Standard Deviation data, 2*STD adalah 95% data kita yang berada di antara mean ± 2* Standard Deviation, dan 3*STD adalah 99.7% data kita yang berada di antara mean ± 3 * Standard Deviation sehingga kita menggangap bahwa data yang sudah melebihi dari 3 * STD sudah berada di posisi 0.3% yang terlalu jauh posisinya dibandingkan mean sehingga bisa dianggap sebagai outlier.
Kesimpulan
Konsep seperti Populasi, Sampel, Measure of Central Tendency, dan Measure of Spread adalah konsep statistik dasar yang harus dipahami oleh Data Scientist. Dengan memahami konsep diatas kita sudah dapat mulai mencoba mengenali seperti apa bentuk data kita.
Yang saya tuliskan diatas adalah beberapa konsep statistik yang sering muncul di dalam pekerjaan sebagai seorang Data Scientist. Di tulisan mendatang saya akan mencoba untuk menuliskan konsep statistik lain yang belum saya singgung seperti inferential statistik ataupun distribusi data.
Jika ada pertanyaan lebih lanjut, kalian selalu dapat menghubungi saya melalui linkedin saya di https://www.linkedin.com/in/cornellius-yudha-wijaya/
Ciao!