
Top Python Packages for Machine Learning Interpretability (Part 1)
You want to have an interpretation for your Machine Learning model


Developing a machine learning model is something that expected from any data scientist. I have come across many data science study that focuses only on the modelling aspect and the evaluation without the interpretation.
However, many haven’t realized the importance of machine learning interpretability in the business process. In my experience, business people would want to know how the model works rather than the metric evaluation itself.
That is why, in this post, I want to introduce you to some of my top python package for machine learning interpretability. However, there are many ML interpretability package I want to introduce, so that I would divide the post into several parts. Let’s get into it!
1. Yellowbrick
Yellowbrick is an open-source Python package that extends the scikit-learn API with visual analysis and diagnostic tools. For Data Scientist, Yellowbrick is used to evaluate the model performance and visualize the model behaviour.
Yellowbrick is a multi-purpose package that you could use in your everyday modelling work. Even though most of the interpretation API from the Yellowbrick is at the basic level, it is still useful for our first modelling steps.
Let’s try the Yellowbrick package with a dataset example. For starter, let’s install the package.
pip install yellowbrickAfter the installation is done, we could use the dataset example from Yellowbrick to test the package.
#Pearson Correlation
from yellowbrick.features import rank2d
from yellowbrick.datasets import load_credit
X, _ = load_credit()
visualizer = rank2d(X)
With one line, we able to visualize the correlation between the features using the Pearson correlation method. It is customizable so that you could use another correlation function.
Let’s try to develop the model to evaluate the model performance and interpret the model. I would use the example dataset from the Yellowbrick user guide and produce a discrimination threshold plot to find the best threshold that separates the binary classes.
from yellowbrick.classifier import discrimination_threshold
from sklearn.linear_model import LogisticRegression
from yellowbrick.datasets import load_spam
X, y = load_spam()
visualizer = discrimination_threshold(LogisticRegression(multi_class="auto", solver="liblinear"), X,y)
Using the Yellowbrick threshold plot, we could interpret that the model performs the best at the 0.4 probability threshold.
If you are curious what Yellowbrick could do, visit the homepage for more info.
2. ELI5
ELI5 is a Python package that helps with machine learning interpretability. Taken from the Eli5 package, the basic usage of this package is to:
inspect model parameters and try to figure out how the model works globally;
inspect an individual prediction of a model and figure out why the model makes the decision.
If Yellowbrick focuses on the features and model performance interpretation, ELI5 focus on the model parameters and the prediction result. Personally, I like ELI5 better because its interpretation is simple enough that business people could understand it.
Let’s try the ELI5 package with a sample dataset and random forest model classifier. I would use the dataset from the seaborn package because it is the simplest one.
#Preparing the model and the dataset
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
mpg = sns.load_dataset('mpg').dropna()
mpg.drop('name', axis =1 , inplace = True)
#Data splitting
X_train, X_test, y_train, y_test = train_test_split(mpg.drop('origin', axis = 1), mpg['origin'], test_size = 0.2, random_state = 121)
#Model Training
clf = RandomForestClassifier()
clf.fit(X_train, y_train)The most basic ELI5 function is to show the classifier weight and the classifier prediction result. Let’s try both functions to understand how the interpretation is coming from.
import eli5
eli5.show_weights(clf, feature_names = list(X_test.columns))
From the above image, you could see that the classifier showing the classifier feature importance with their deviation. You could see that the displacement feature is the most important feature, but they have a high deviation, indicating bias within the model. Let’s try to show the prediction result interpretability.
eli5.show_prediction(clf, X_train.iloc[0])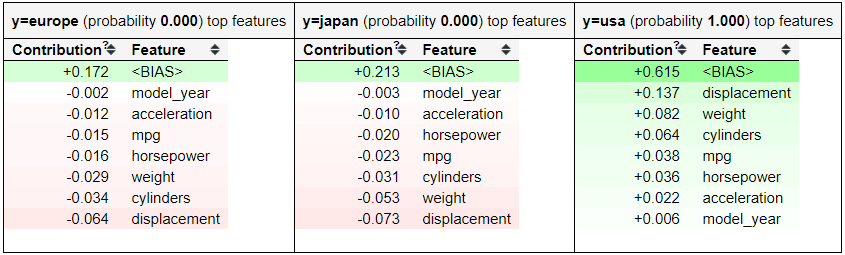
Using the show prediction function by ELI5, we could get the feature contribution information. What features contribute to certain prediction results, and how much is the probability shifting by these features. This is a good function for you to interpret the model prediction easily to the business people.
However, it would be best to remember that the function above is based on the tree interpretation (because we use the Random Forest model). It might be good enough to give you an interpretation for the business people; however, it might be biased because of the model. That is why ELI5 offer another way to interpret the Black-box model based on the model metric—It is called Permutation Importance.
Let’s try the Permutation Importance function as a starter.
#Permutation Importance
perm = PermutationImportance(clf, scoring = 'accuracy',
random_state=101).fit(X_test, y_test)
show_weights(perm, feature_names = list(X_test.columns))
The idea behind permutation importance is how the scoring (accuracy, precision, recall, etc.) shift with the feature existence or without it. In the above result, we can see that displacement has the highest score with 0.3013. When we permute the displacement feature, it will change the accuracy of the model as big as 0.3013. The value after the plus-minus sign is the uncertainty value. The permutation Importance method is inherently a random process; that is why we have the uncertainty value.
The higher the position, the more critical the features are affecting the scoring. Some feature in the bottom place shows a minus value, which is interesting because it means that the feature increases the scoring when we permute the feature. This happens because, by chance, the feature permutation actually improves the score.
Personally, ELI5 has given me enough machine learning interpretability for the business people, but there is still some Python package that I want to introduce to you.
3. SHAP
It will not complete if we are talking about Machine Learning Interpretability without mentioning SHAP. For you who never heard about it, SHAP or (SHapley Additive exPlanations) is a game-theoretic approach to explain the output of any machine learning model. In a simpler term, SHAP using the SHAP values to explain the importance of each feature. SHAP use the SHAP values difference between the prediction of the model and the null model developed. SHAP is model agnostic, similar to the Permutation Importance, so it is useful for any kind of model.
Let’s try using the sample dataset and model to explain SHAP in more detail. First, we need to install the SHAP package.
#Installation via pip pip install shap #Installation via conda-forge conda install -c conda-forge shapIn this sample, I would use the titanic sample dataset and only rely on the numeric columns. This is only for sample purposes and should not become the standard for data analysis.
#Preparing the model and the dataset from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split titanic = sns.load_dataset('titanic').dropna() titanic = titanic[['survived', 'age', 'sibsp', 'parch']] #Data splitting for rfc X_train, X_test, y_train, y_test = train_test_split(titanic.drop('survived', axis = 1), titanic['survived'], test_size = 0.2, random_state = 121) #Model Training clf = RandomForestClassifier() clf.fit(X_train, y_train)We already trained our data with the titanic data, and now we could try to interpret the data with SHAP. Let’s use the global interpretability of the model to understand how SHAP work.
import shap
shap_values = shap.TreeExplainer(clf).shap_values(X_train) shap.summary_plot(shap_values, X_train)
As we can see from the result, we could interpret that the age feature contributes the most to the prediction result. If you want to look at the specific class contribution to the prediction, we only need to tweak the code a little. Let’s say we want to look at class 0, which means we use the following code.
shap.summary_plot(shap_values[0], X_train)
From the image above, we could see the contribution of each data into the prediction probability. The redder the colour, the higher the value and vice versa. Also, when the value is on the positive side, it contributes to the class 0 prediction result probability and vice versa.
SHAP is not limited to global interpretability; it also gives you the function to interpret individual dataset. Let’s try to interpret the prediction result for the first row.
explainer = shap.TreeExplainer(clf)
shap_value_single = explainer.shap_values(X = X_train.iloc[0,:])
shap.force_plot(base_value = explainer.expected_value[1],
shap_values = shap_value_single[1],
features = X_train.iloc[0,:])
As you can see from the image above, the prediction is closer to class 0 because it is pushed by the age and sibsp feature and only a little contribution by the parch feature.
Conclusion
Machine Learning Interpretability is an important tool for any data scientist because it allowed you to communicate your result better to the business user.
In this post, I have outline 3 ML interpretability Python Package:
Yellowbrick
ELI5
SHAP
Let’s continue our learning in the next part. I hope it helps!