
Top Python Packages for Machine Learning Interpretability (Part 2)
You know you need Interpretability


Continuing our previous discussion— if you missed Part 1 of Machine Learning Interpretability, you could visit it here. We would now visit another Python package used for the Machine Learning Interpretability. Let’s get into it.
4. Mlxtend
Mlxtend or machine learning extensions is a Python package for data science everyday work life. The APIs within the package is not limited to interpretability but extend to various functions, such as statistical evaluation, Data Pattern, Image Extraction, and many more. However, we would discuss the API for interpretability for our current article—the Decision Regions plotting.
The Decision Regions plot API would produce a decision region plot to visualize how the feature decides the classification model prediction. Let’s try using sample data and a guide from Mlxtend.
First, we need to install the Mlxtend package.
pip install MlxtendThen we use the sample dataset and develop a model to see the Mlxtend in action.
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import itertools
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import EnsembleVoteClassifier
from mlxtend.data import iris_data
from mlxtend.plotting import plot_decision_regions
# Initializing Classifiers
clf1 = LogisticRegression(random_state=0)
clf2 = RandomForestClassifier(random_state=0)
clf3 = SVC(random_state=0, probability=True)
eclf = EnsembleVoteClassifier(clfs=[clf1, clf2, clf3], weights=[2, 1, 1], voting='soft')
# Loading some example data
X, y = iris_data()
X = X[:,[0, 2]]
# Plotting Decision Regions
gs = gridspec.GridSpec(2, 2)
fig = plt.figure(figsize=(10, 8))
for clf, lab, grd in zip([clf1, clf2, clf3, eclf],
['Logistic Regression', 'Random Forest', 'RBF kernel SVM', 'Ensemble'],
itertools.product([0, 1], repeat=2)):
clf.fit(X, y)
ax = plt.subplot(gs[grd[0], grd[1]])
fig = plot_decision_regions(X=X, y=y, clf=clf, legend=2)
plt.title(lab)
plt.show()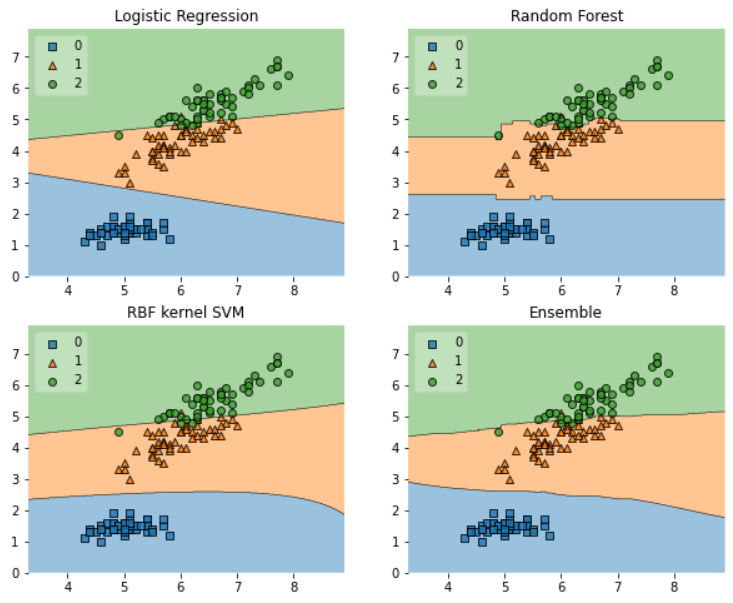
From the above plot, we could interpret the decision made by the model. You could see the differences between each model when they make the prediction. For example, the Logistic Regression model prediction result for class 1 is getting bigger the higher the X-axis value is but didn’t have too much change on the Y-axis. It contrasts with the Random Forest model, where the division is not changing much following the X-axis value, and the Y-axis value seems constant for every prediction.
The only weakness for the decision region is that it is limited to 2 Dimension features, so it is more useful for pre-analysis than the actual model itself. However, it is still useful for the conversation with the business people.
5. PDPBox
PDP or Partial Dependence Plot is a plot that shows the marginal effect of features on the predicted outcome of the machine learning model. It is used to evaluate whether the correlation between the feature and target is linear, monotonic, or more complex.
The advantage of interpreting with a Partial Dependence plot is easy to interpret for business people. This is because the partial dependence function computation is intuitive enough for people to understand: The calculation for the partial dependence plots has a causal interpretation when we intervene on a feature, and we measure the changes in the predictions; this is when we could measure the interpretation.
Let’s try using the sample data from the user guide to understand the PDPBox even more. First, we need to install the PDPBox package.
pip install pdpboxThen we could try to follow the user guide for more information on how PDPBox helping us create interpretable Machine Learning.
import pandas as pd
from pdpbox import pdp, get_dataset, info_plots
#We would use the data and model from the pdpbox
test_titanic = get_dataset.titanic()
titanic_data = test_titanic['data']
titanic_features = test_titanic['features']
titanic_model = test_titanic['xgb_model']
titanic_target = test_titanic['target']When we have our data and model, let’s try one of the functions to check the information between the feature and the target using the info plots function.
fig, axes, summary_df = info_plots.target_plot(
df=titanic_data, feature='Sex', feature_name='gender', target=titanic_target
)
_ = axes['bar_ax'].set_xticklabels(['Female', 'Male'])
You could get the statistical information of the target and the feature with one function. It is easy to explain to the businesspeople using this function. Let’s check the model prediction distribution function along with the features.
fig, axes, summary_df = info_plots.actual_plot(
model=titanic_model, X=titanic_data[titanic_features], feature='Sex', feature_name='gender'
) 
Now, let’s move on to use the PDP plotting function to interpret our model prediction.
pdp_sex = pdp.pdp_isolate(
model=titanic_model, dataset=titanic_data, model_features=titanic_features, feature='Sex'
)
fig, axes = pdp.pdp_plot(pdp_sex, 'Sex')
_ = axes['pdp_ax'].set_xticklabels(['Female', 'Male'])
From the above image, we could interpret that the prediction probability is decreased when the sex feature is Male (means that Male less likely to survived). This is how we use PDPbox to have model interpretability.
6. InterpretML
InterpretML is a Python Package that includes many Machine Learning Interpretability API. The purpose of this package is to give you an interactive plot based on plotly to understand your prediction result.
InterpretML offers you many ways to interpret your Machine Learning (Globally and Locally) by using many of the techniques we have discussed—namely SHAP and PDP. Also, this package owns a Glassbox model API which gives you an interpretability function when you develop your model.
Let’s try this package with a sample dataset. First, we need to install the InterpretML.
pip install interpretI want to give you an example by using the glass box model that InterpretML because, for me personally is interesting to use. Let’s try to develop the model by using the titanic dataset sample.
from sklearn.model_selection import train_test_split
from interpret.glassbox import ExplainableBoostingClassifier
import seaborn as sns
#the glass box model (using Boosting Classifier)
ebm = ExplainableBoostingClassifier(random_state=120)
titanic = sns.load_dataset('titanic').dropna()
#Data splitting
X_train, X_test, y_train, y_test = train_test_split(titanic.drop(['survived', 'alive'], axis = 1),
titanic['survived'], test_size = 0.2, random_state = 121)
#Model Training
ebm.fit(X_train, y_train)
Using the glass box model from the InterpretML, it would automatically One Hot Encoding your features and feature engineering the interaction feature for you. Let’s try to get a global explainable for this model.
from interpret import set_visualize_provider
from interpret.provider import InlineProvider
set_visualize_provider(InlineProvider())
from interpret import show
ebm_global = ebm.explain_global()
show(ebm_global)
From the image above, we could see the summary of the model feature importance. It shows you all the feature that deemed important based on the model feature importance.
The explainable is an interactive plot that you could use to explain the model more specifically. If we only see the summary in the above image, we could select another component to specify the feature you want to see. In this way, we could explain how the feature in the model affecting the prediction.
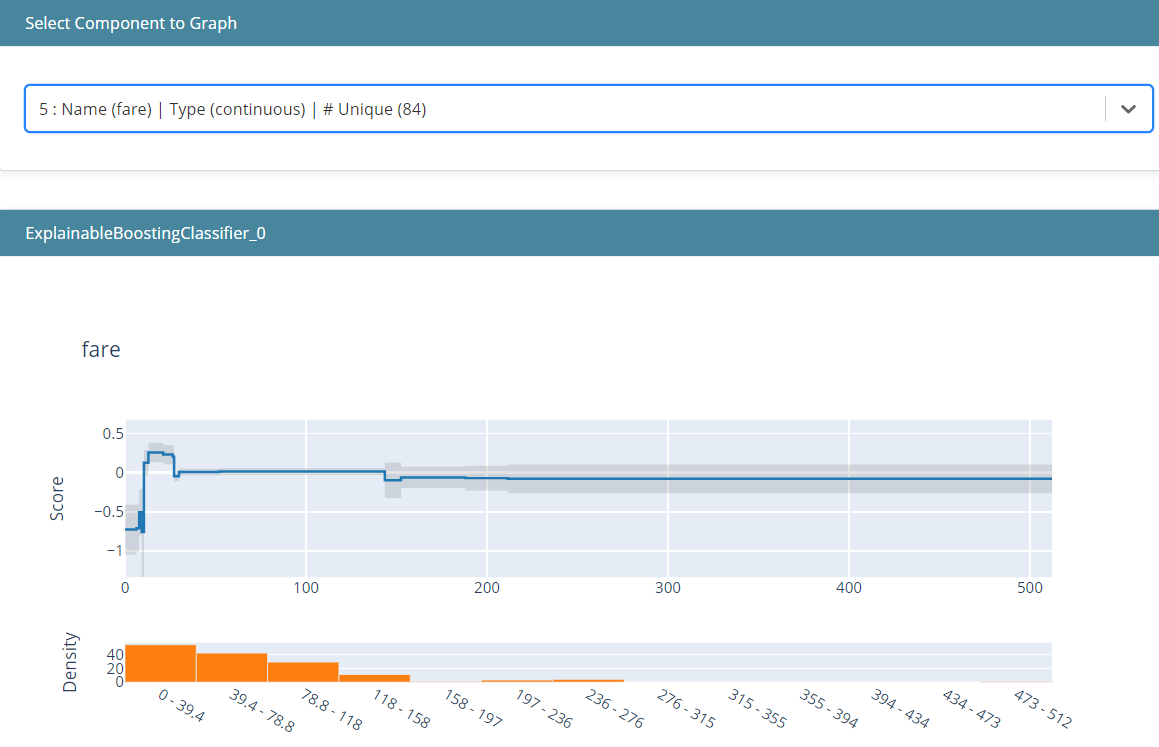
In the image above, we could see that low fare decreasing the chance of survival, but as the fare getting higher, it increases the survival chance. However, you could see the density and the bar chart—many people are coming from a lower fare.
Often time, we are not only interested in the Global interpretability but also the Local. In this case, we could use the following code to interpret it.
#Select only the top 5 rows from the test data
ebm_local = ebm.explain_local(X_test[:5], y_test[:5])
show(ebm_local)
Local interpretability shows how a single prediction is made. According to the user guide, the values shown here are log-odds scores from the model, which are added and passed through a logistic-link function to get the final prediction. We could see the sex male giving the most contribution to lowering the survival chance in this prediction.
Conclusion
Machine Learning Interpretability is an important tool for any data scientist because it allowed you to communicate your result better to the business user. If you missed Part 1 of Machine Learning Interpretability, you could visit it here.
In this post, I already outline another 3 ML interpretability Python Package:
Mlxtend
PDPBox
InterpretML
I hope it helps!