
Why Most GenAI Workflows Need a Review Loop
A Better Prompt Is Not Enough


Most teams spend their time improving the prompt. They reword the instructions, add examples, or switch to a stronger model, and the output usually improves. But there is a limit to this. A prompt only produces one attempt. The model writes a draft and stops. It does not tell you whether the draft is correct, and it does not improve on its own the next time you run it.
In an earlier article, I argued that reliability depends on the entire workflow, not just the final answer, and that you should check the workflow at each step rather than only the end result. Evaluation is useful, but it only measures how good an output is. It does not improve the output. To improve the output, you need a review loop: a repeatable process that checks the result, identifies what went wrong, fixes it, and records what you learned so the next run improves. The rest of this article explains the idea and then builds one in Python that you can run today.
In short, evaluation measures how good an output is. A review loop is the process that improves it.
A prompt cannot check its own work
A single prompt is one pass through the model. It cannot check its own work, it does not remember the previous run, and it has no rule for deciding when the task is complete. In practice, the model is finished when it stops producing text, which is not the same as being correct.
Anthropic describes a more reliable setup called the evaluator-optimizer pattern. One model writes the draft, and a second model grades it against clear criteria. The draft is then revised until it meets those criteria. Anthropic recommends this when you have clear criteria and when revising the output actually improves it, which covers most real work. Its Claude Code guidance makes a related point: if the system cannot check its work against something concrete, such as a test, a schema, or a second reviewer, then deciding whether the work is done becomes a matter of opinion, and a person has to check everything by hand.
OpenAI gives similar advice. Reliable quality comes from clear goals, test datasets, automated graders, and ongoing evaluation, rather than from a single well-written prompt. Reliability is something you build a process around, not something you reach through wording alone.
Common ways the first draft goes wrong
A draft can read well and still be wrong. This happens because of how the models are trained. Below are three common problems. The model cannot detect any of them on its own, which is why an outside check is needed.
Models tend to guess. They are trained to produce text that sounds plausible, not text that has been verified. TruthfulQA found that models often repeat common misconceptions. OpenAI’s 2025 research on hallucinations offers one reason: most training rewards confident answers more than admitting uncertainty, so the model learns to guess rather than say it does not know.
Models can overlook the middle of a long input. Even with large context windows, they do not treat every part of the input equally. The Lost in the Middle research found that information in the middle of a long input is often underused, while information at the start and end gets more weight. For summaries and retrieval-based systems, an important detail can be present in the input but missing from the output.
Models tend to agree with the user. Research on sycophancy found that several assistants often match the user’s stated opinion, and that people sometimes prefer an agreeable answer to a correct one. This matters at work, where prompts often suggest the answer the writer expects. If you ask whether the data supports your plan, the model is more likely to agree than to disagree.
Takeaway: These are normal limits of how the models work. A review loop is there to catch the mistakes the model cannot catch on its own.
The four-stage review loop
The review loop has four stages. It applies to ordinary documents as well as to code.
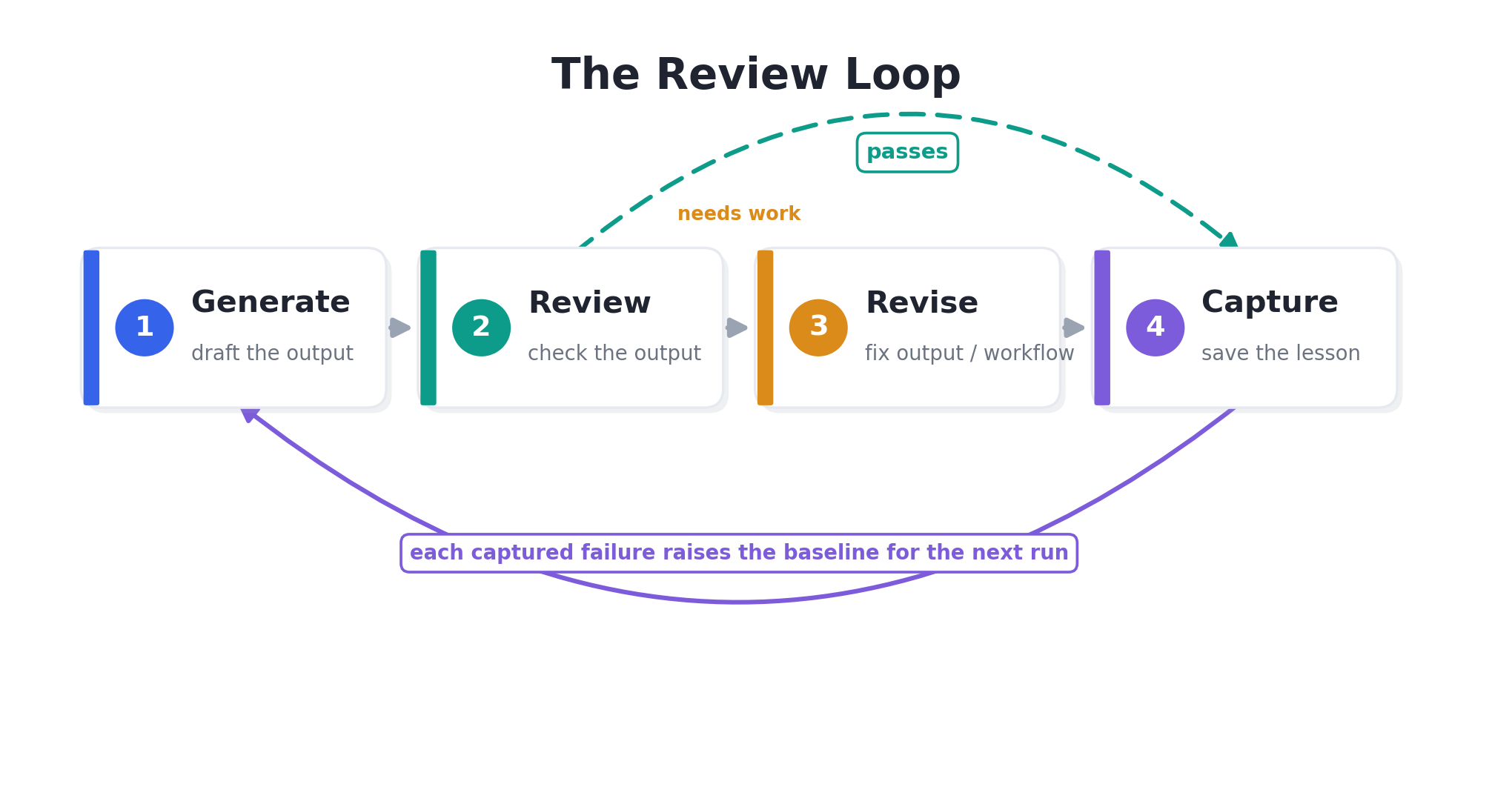
Generate. Produce the first draft, however your workflow does it: a prompt chain, retrieval, or tool calls.
Review. Check the draft with code first, then with a second model, and send the hard cases to a person. The claims, the structure, the process that produced it, and safety are all fair game.
Revise. Fix the problems found in the review. You can fix the output itself, or fix the workflow that produced it. Re-running with feedback fixes the current draft. Fixing the instruction or the retrieval step also improves future drafts, which has a larger effect over time.
Capture. This stage is often skipped, but it is what makes the loop worth running. Record each failure in a reusable form, such as a test case, an evaluation example, a rule, or a guardrail. OpenAI recommends expanding your evaluation set using real production data. Anthropic describes the shift from repeatedly fixing the same problem to a system in which each failure becomes a test that prevents it from recurring.
Takeaway: If you find a failure but do not record it, the same problem can return on a later run.
Building it: clean data from a document
Here is the loop applied to a common task: pulling fields out of a messy invoice into validated JSON. The output looks fine at a glance, which is exactly when a review loop earns its place. The code is provider-agnostic, so replace call_model with your own client and install jsonschema.
Start with the input. This is the kind of text a model reads easily but gets subtly wrong:
INVOICE Acme Industrial Supply
Inv #: AC-10827 Date: 03/14/2025
Bill to: Northwind Trading
2 x Steel bracket (SB-12) ............ 24.00
10 x Hex bolt M8 @ 3.50 ea ........... 35.00
1 x Safety gloves, pair .............. 12.75
Subtotal: 71.75
Tax (8%): 5.74
TOTAL DUE: 77.49The setup is your model call and a few imports:
"""Structured extraction with a review loop (provider-agnostic).
Needs the standard library plus jsonschema (pip install jsonschema).
Replace call_model with your own client (OpenAI, Anthropic, ...).
"""
import json
import re
from datetime import date
from jsonschema import validate, ValidationError
def call_model(prompt: str) -> str:
"""Send the prompt to your model and return its text reply."""
raise NotImplementedErrorA schema fixes the shape, so structure and types are checked for free:
# The shape we require. The schema checks structure and types for free.
SCHEMA = {
"type": "object",
"required": ["invoice_number", "date", "vendor", "customer",
"line_items", "subtotal", "tax", "total"],
"properties": {
"invoice_number": {"type": "string"},
"date": {"type": "string"},
"vendor": {"type": "string"},
"customer": {"type": "string"},
"line_items": {"type": "array", "items": {
"type": "object",
"required": ["description", "quantity",
"unit_price", "amount"],
"properties": {
"description": {"type": "string"},
"quantity": {"type": "number"},
"unit_price": {"type": "number"},
"amount": {"type": "number"},
},
}},
"subtotal": {"type": "number"},
"tax": {"type": "number"},
"total": {"type": "number"},
},
}
Deterministic checks run first because they are cheap and exact. They catch the arithmetic and the invented numbers that a fluent answer hides:
# Deterministic checks: cheap, exact, and run first. These catch the
# arithmetic and made-up numbers that a fluent draft hides.
def near(a, b, tol=0.01):
return abs(a - b) <= tol
def check_extraction(data, source):
issues = []
for item in data["line_items"]:
if not near(item["quantity"] * item["unit_price"], item["amount"]):
issues.append("line '%s': qty x price != amount"
% item["description"])
if not near(sum(i["amount"] for i in data["line_items"]),
data["subtotal"]):
issues.append("line amounts do not sum to subtotal")
if not near(data["subtotal"] + data["tax"], data["total"]):
issues.append("subtotal + tax != total")
for field in ("invoice_number", "total"):
if str(data[field]) not in source:
issues.append("%s '%s' is not in the document"
% (field, data[field]))
try:
date.fromisoformat(data["date"])
except ValueError:
issues.append("date '%s' is not ISO format" % data["date"])
return issues
Some mistakes are not arithmetic. A second model called reviews the extraction against the source and catches things like swapped names:
# Independent reviewer: a second model call catches what code cannot,
# such as a vendor and customer that have been swapped.
JUDGE = (
"You verify an invoice extraction against the SOURCE.\n"
"Reply ONLY with JSON: {\"passed\": bool, \"issues\": [string]}.\n"
"Check that names, descriptions, and roles match the document."
)
def judge_extraction(source, data):
prompt = (JUDGE + "\n\nSOURCE:\n" + source
+ "\n\nEXTRACTION:\n" + json.dumps(data, indent=2))
return json.loads(call_model(prompt))Capture writes every failure to a file you can replay later:
# Capture: every failure becomes a row you can replay later as a test.
def capture(source, data, issues, path="eval_set.jsonl"):
row = {"source": source, "output": data, "issues": issues}
with open(path, "a") as handle:
handle.write(json.dumps(row) + "\n")The loop puts it together: generate, run the cheap checks, then the judge, capture failures, revise, and stop after a few tries:
# The loop: generate, review (code, then judge), capture, revise, repeat.
EXTRACT = (
"Extract this invoice as JSON matching the agreed schema. "
"Use ISO dates (YYYY-MM-DD) and copy every number exactly.\n\n"
"INVOICE:\n"
)
def extract_invoice(source, max_tries=3):
prompt = EXTRACT + source
for attempt in range(1, max_tries + 1):
print("Attempt %d" % attempt)
try:
data = json.loads(call_model(prompt)) # generate
validate(instance=data, schema=SCHEMA)
issues = check_extraction(data, source) # review: code
except (json.JSONDecodeError, ValidationError) as error:
data, issues = {}, ["invalid output: " + str(error)[:50]]
print(" code checks:", "FAIL" if issues else "PASS")
if not issues: # review: judge
verdict = judge_extraction(source, data)
issues = [] if verdict["passed"] else verdict["issues"]
print(" judge:", "FAIL" if issues else "PASS")
if not issues:
print(" accepted")
return data
for problem in issues:
print(" - " + problem)
capture(source, data, issues) # capture
prompt = (EXTRACT + source + "\n\nYour last answer had:\n"
+ "\n".join("- " + p for p in issues)
+ "\n\nReturn corrected JSON.") # revise
raise RuntimeError("still failing; escalate to a human")Running it on the invoice above produces the trace below. The first draft is fluent but wrong in two different ways:
Attempt 1
code checks: FAIL
- subtotal + tax != total
- total '77.94' is not in the document
Attempt 2
code checks: PASS
judge: FAIL
- vendor/customer swapped: seller is Acme Industrial Supply
Attempt 3
code checks: PASS
judge: PASS
acceptedAttempt 1 fails the cheap checks: the total does not match subtotal plus tax, and 77.94 never appears in the document. Attempt 2 fixes the math, but the judge notices the vendor and customer are swapped. Attempt 3 passes both and is accepted. These are the failure modes from earlier in action: a confident wrong number, then a confident wrong label, both caught before release. Two failures were written to eval_set.jsonl on the way.
Those captured failures are not just logs. Replay them as tests, and a bug you have already fixed cannot quietly come back:
# regression.py: replay captured failures; they should pass now.
import json
from rloop import extract_invoice, check_extraction
def test_known_failures_now_pass():
for line in open("eval_set.jsonl"):
case = json.loads(line)
fixed = extract_invoice(case["source"])
assert check_extraction(fixed, case["source"]) == []Three kinds of review
That example used all three kinds of review, and most real systems need them together.
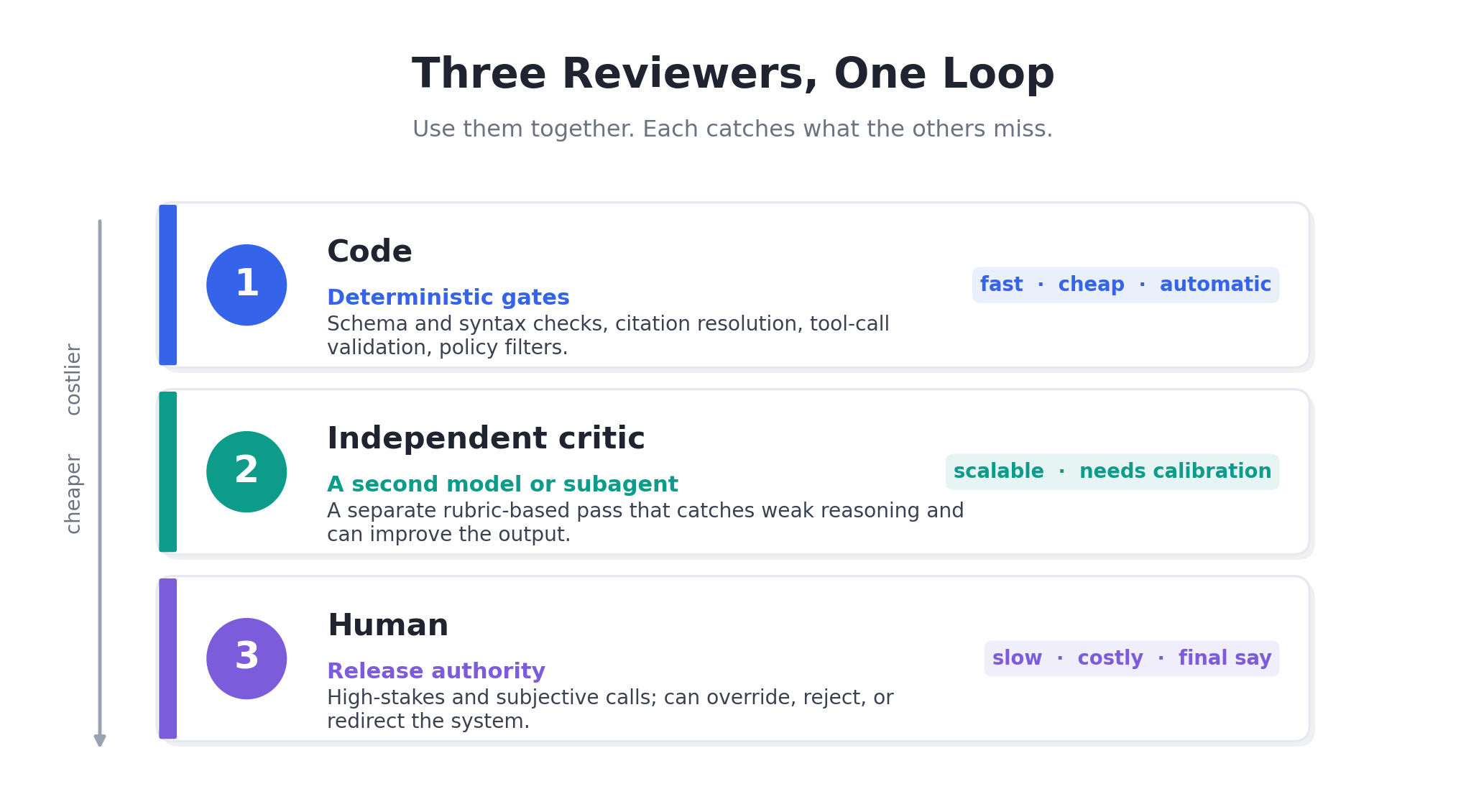
Code handled everything with a clear answer: the schema, the arithmetic, the date format, and the check that numbers came from the source. It is fast and exact, and it caught the bad total. Anthropic, OpenAI, and Microsoft all treat these checks as the base of a good pipeline.
An independent reviewer, a separate model call with its own rubric, caught the swapped names that code cannot judge. Self-Refine, CRITIC, and Reflexion all report real gains from this kind of separate critique. One caution from my earlier article: a model reviewer has their own biases, so check it against human judgment from time to time rather than trusting it on its own.
A person with authority is the last step, for high-stakes or subjective cases. In the code that is raised at the end, when the loop cannot pass on its own, it stops and hands off instead of shipping. NIST’s Generative AI Profile recommends that pre-deployment testing reach the people who decide what gets released.
Takeaway: One layer of review is rarely enough. Using code, an independent reviewer, and a person together covers more types of error.
What repeatability actually means
It is worth being clear about what repeatability means here. It does not mean the model produces the same text every time, because it is not deterministic. It means the quality stays within a predictable range even as the wording changes.
The loop does not remove that variation, but it keeps the results within known limits. In practice, this lets you describe the worst case in advance. The schema check will not allow malformed output, the arithmetic check will not allow a total that does not add up, and the grounding check will not allow a number that is not in the source. The wording can vary; those guarantees do not.
Review is becoming a compliance requirement
There is also a practical reason beyond quality. Review and oversight are increasingly expected. NIST’s Generative AI Profile asks teams to verify sources before and after launch, monitor for issues that require human attention, and keep records. Microsoft’s code of conduct for its AI services requires ongoing testing, feedback channels, and human oversight, and does not permit significant decisions without it. The EU AI Act requires that people be told when they are interacting with AI or reading AI-generated content.
Several well-known cases show what can happen without review. Each one failed in a different way:
CNET. A review of its AI-written finance articles found that 41 of 77 needed corrections. The articles were published because no one checked them first.
Air Canada. A tribunal held the airline responsible after its chatbot described a refund policy that did not exist, and rejected the argument that the chatbot was a separate entity.
Avianca. Lawyers were sanctioned for submitting a court filing that cited cases that did not exist.
In each case, the writing looked fine. What was missing was a review step before the work was released.
Conclusion
The main point is straightforward. Evaluation tells you how good an output is. A review loop is how you improve it. The four stages, the three kinds of review, and the governance requirements are all parts of that process.
As the example shows, the loop is mostly ordinary code: a schema, a few exact checks, a second opinion, and a record of past failures. The useful change is to spend less time refining the prompt and more time on the surrounding process: what gets checked, who can reject the output, what counts as a failure, when you rerun it, and how each failure becomes a permanent check. With those pieces in place, generative AI can move from producing one-off drafts to supporting a process you can rely on.