
Why Simple Solution Usually Works in Data Science?
Don't overcomplicate the problem that you need to solve


Have you ever heard about Occam’s Razor principle? It’s a principle stating that “the simplest solution is usually the best one.” It means that when presented with several solutions to solve the problem with the same result, we should prefer the one with the simplest one. The Occam Razor principle itself fully applies to the world of data science.
Let’s see from the data science realm. I would say that many people who enter the data field, or even professionals, love to use the latest technology. For example, people hurriedly implemented the LLM as they didn’t want to be left behind by the advanced technology. Yet, does the business even need it?
The value of the data science project is how the solution could quickly solve the business problem with data usage. Complicated solutions might work, but would they truly be the best solution? This is the premise of our discussion in this article.
The Appeal of Complexity in Data Science
There is an attraction to complex solutions in data science. This came from a belief that sophisticated or complex models are inherently more accurate and powerful. I am sure many beginner data scientists would have this belief, as the complex model often taught last.
The belief is also often found within many practitioners where we equate complexity with advanced capabilities, assuming the algorithm’s complex parameter would directly correlate with their ability to decipher patterns in data.
It’s even fueled by the industry's competitive nature, where showcasing technical proficiency with advanced models can be seen as prideful. Additionally, the advancement in computational power and data availability has enabled the development of these complex models, making them more accessible and tempting.
However, this image of complexity can be misleading. Complex solutions often require more resources and time to develop, and their inherent nature can lead to maintenance, interpretation, and practical application challenges.
I would write more in-depth about the model complexity effect that affects our model choices, but let’s continue with the discussion.
Benefits of Simple Solution
The benefits of simplicity in data science are many and significant.
Firstly, simple solutions are usually easier to implement and understand. The simple model could accelerate the development time and make the model more understandable to the business teams, including those who may not have technical knowledge.
Secondly, simple models are often more reliable and efficient. They tend to require fewer computational resources, making them more sustainable and cost-effective. Additionally, these models are not easy to overfit, although underfitting might become the other problem as high bias is present in the simple model.
Another key advantage is the simpler solutions' ease of interpretation and explainability. Explaining and justifying decision-making processes is essential in an era where transparency in the machine learning model is increasingly important. Simple models often provide more precise insights into how input variables influence the output, making identifying and correcting biases easier.
Moreover, simplicity in data science aligns well with the principle of Occam’s Razor, which we have stated previously. In practice, a simpler model with fewer parameters and assumptions is often preferable, as it is more likely to generalize well to unseen data.
An example of the power of simplicity is the case of the Netflix Prize. While the winning team combined over 100 algorithms to improve the movie recommendation system, Netflix ultimately implemented a much simpler solution. The reason is that the winning model was difficult to maintain, and the increase in accuracy did not justify the additional complexity and computational expense.
The comparison between simpler and complex solutions can be seen in the table below.


Balancing Simplicity and Complexity
In data science, a balance between simplicity and complexity is essential. This is usually what we refer to as the bias-variance tradeoff.
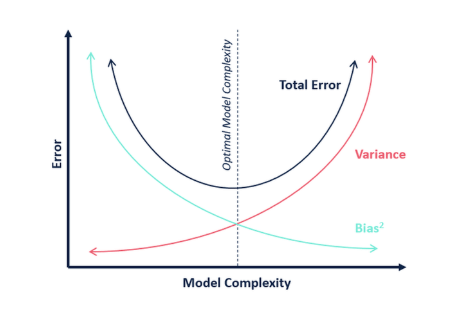
Simple models, while easy to implement and interpret, may not capture complex data patterns effectively. That’s why the bias is higher.
Complex models, offering greater flexibility, can be resource-intensive and prone to overfitting because of the high variance.
The key lies in starting with a simple model and incrementally adding the complexity as needed based on the evaluation. This approach ensures a performance improvement with an increase in complexity. We need to adjust it based on the project requirements as well.
Conclusion
The choice between simple and complex models in data science is not a matter of which one is better. Instead, it's about finding a balance that suits each project's needs.
Simple solutions offer ease of use and clarity, while complex solutions provide depth and flexibility.
The key is to start simple and increase the complexity as needed.
Thank you, everyone, for subscribing to my newsletter. If you have something you want me to write or discuss, please comment or directly message me through my social media!