
You Should Not Standardize Your Data!

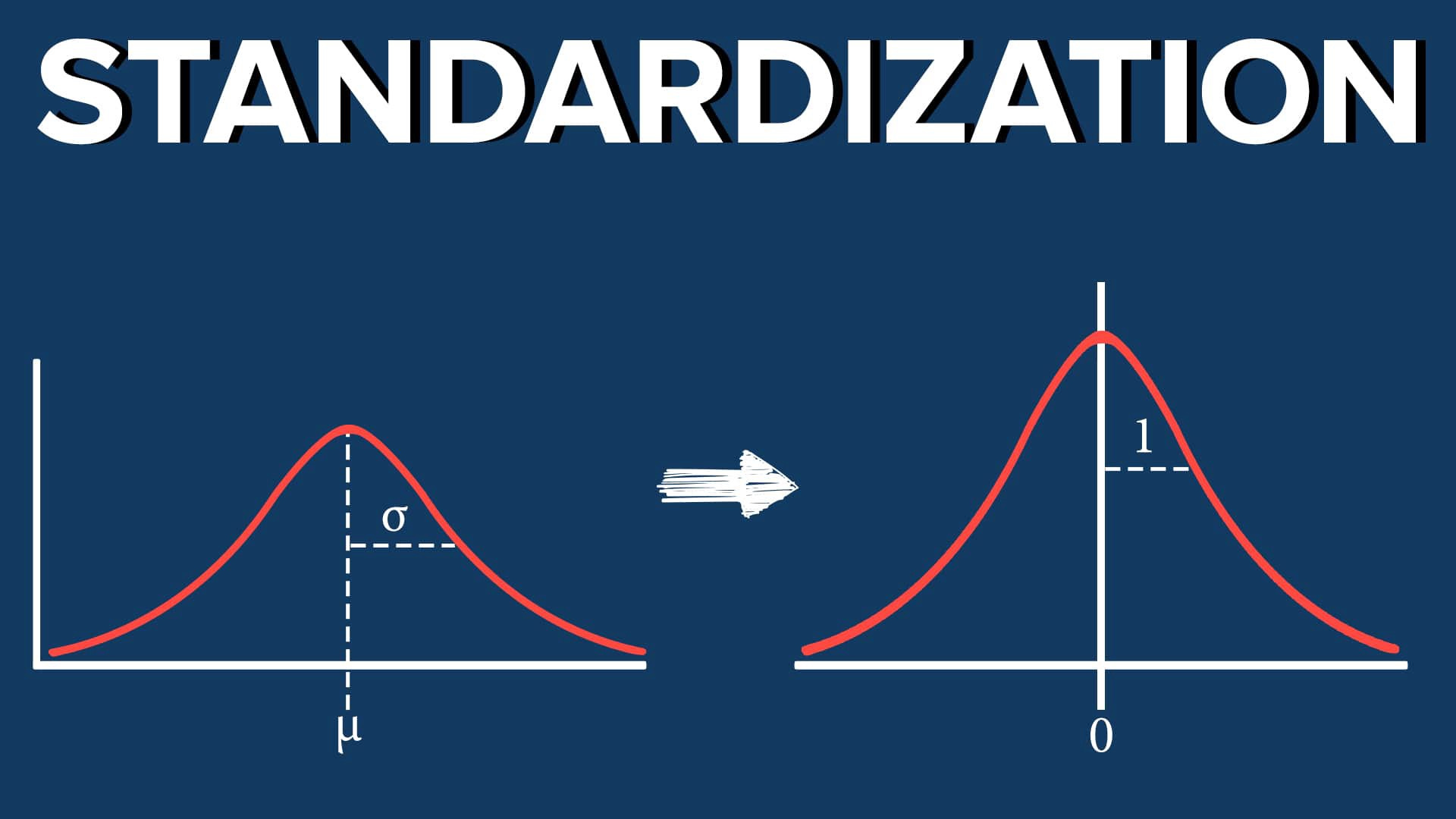
Well, to be precise, you should not always standardize your data.
There are times when you could standardize and when you shouldn’t.
Here are a few reasons why you might not want to standardize your data:
Your data is on the same scale.
You might not need to standardize your data if the variables are already on the same scale. For example, if you have a dataset measuring height and weight in meters and kilograms, there is no need to standardize the data.
Your data is categorical or ordinal.
Standardization is primarily used for numerical data that are measured on a continuous scale. Even if you do categorical encoding, you don’t need to standardize the variable.
Your machine learning is insensitive to different scales.
Not all ML algorithms require data on the same scale. For example, decision trees and random forests are insensitive to the scale of the variables. Standardization might not improve your model performance at all.
The data contains outliers.
Standardization uses means and standard deviation parameters, which are affected by the outlier. In this case, alternative methods for resisting outliers, such as robust scaling, are more appropriate.
Learn carefully when you should standardize the data to avoid the negative effect. It’s necessary if we want the best result from our model.
That is all for today! Please comment if you want to know something else from Machine Learning and Python domain!