
Is It Necessary For Feature Scaling in Tree-Based Models? - NBD Lite #20
Would it be a futile attempt?

If you are interested in more audio explanations, you can listen to the article in the AI-Generated Podcast by NotebookLM!👇👇👇
Many data scientists often use feature scaling by default.
It’s something that has become a standard in data science education.
Some can argue that you should done feature scaling if it is really necessary—Which is something we will discuss today.
Is Feature Scaling necessary for Tree-Based Models?

For context about feature scaling, you might want to check out our previous NBD Lite series on normalization and standardization!

How Does Tree-Based Model Work?
Referring to the previous series about Common Classification Machine Learning, we briefly discussed how they work.
Tree-based models such as Decision Tree use a flowchart-like structure to split data based on the data.
It would then make decisions by going down the tree until it reaches a terminal node (leaf) to make a decision.
Usually, it decides where to split by using the Gini Index or Entropy.
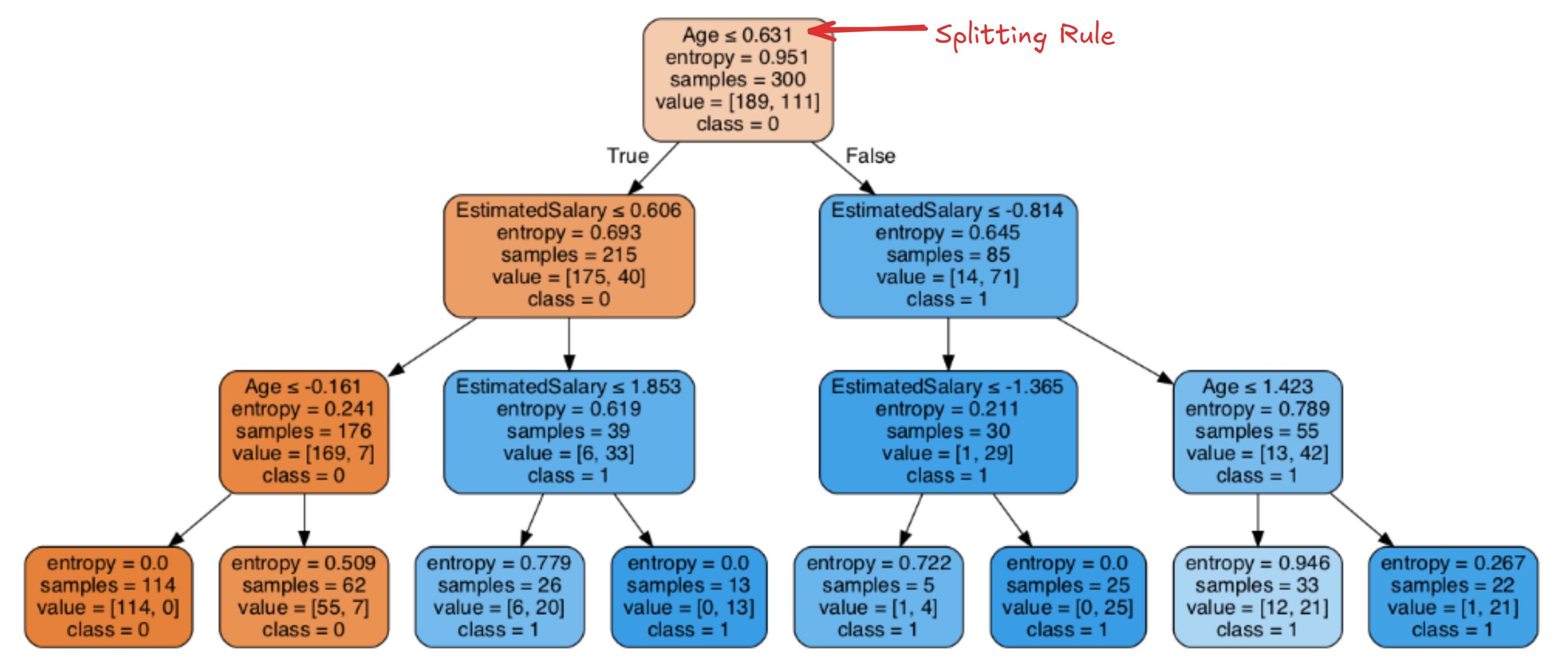
In the image above, the decision tree works by having a splitting rule that the nodes follow until the terminal node decides the classification.
However, how does it relate to feature scaling?
Feature Scaling in Tree-Based Model
Feature scaling involves transforming the data so that all features are on a similar scale, usually through normalization or standardization.
The process is important if the algorithms rely on distance calculations, as the unit differences could skew the result.
Support Vector Machines (SVM), K-nearest neighbors (KNN), and linear regression models, for example, rely on distance.
Well, Tree-based models operate differently from distance-based algorithms.
As mentioned above, the Tree-Based model recursively splits the dataset into subsets based on feature values, creating branches that lead to the final prediction.
Basically, the model does not rely on the distance between features but rather on their relative ordering and ability to create pure subsets.
The Gini Index and Entropy we used for creating the splitting rule are not affected by the scale and are more about the proportions or probabilities of classes within the subsets.
Consider a feature with values [1, 10, 100, 1000] and a binary target variable.
Whether these values are scaled to [0.001, 0.01, 0.1, 1] or standardized to [–1.5, –0.5, 0.5, 1.5], the relative order is still [smallest to largest].

The splits and the resulting Gini Index or Entropy calculations are unaffected, as the tree only cares about how many samples fall on either split.
This means the feature scale does not affect the tree's structure and decision-making, making feature scaling unnecessary.

Impact on the Workflow
Given that tree-based models are insensitive to feature scaling, It’s only adds unnecessary complexity to our workflow:
Unnecessary Preprocessing as it adds an extra step to the preprocessing pipeline and might extend model training unnecessarily.
No Performance Benefit as it does not improve accuracy, model structure, or predictive power.
Overall, feature scaling might not be necessary for a Tree-Based model.
Situation to use Feature Scaling in Tree-Based Model
As much as the feature scaling is not necessary for the tree-based model, there are situations in which you might want to use it:
When you combine tree-based models with other algorithms sensitive to feature scaling, such as the ensemble algorithm.
In cases of applying L1 (Lasso) or L2 (Ridge) regularization in a gradient-boosting model, feature scaling could be beneficial.
Using algorithms that mix distance-based methods with tree-based structures, such as Isolation Forest.
There might be more situations where scaling can be beneficial, but feature scaling is unnecessary in a standard tree-based model.
That’s all for today! I hope this helps you understand the necessity of feature scaling in a tree-based model.
Are there any more things you would love to discuss? Let’s talk about it together!
👇👇👇